
Índice
- Introdução
- O Prompt
- A Resposta
- Como as métricas foram coletadas?
- Resultados do Benchmark
- Resultados Resumidos
- Conclusão
Introdução
Olá,
Com o novo hype de IA (Jan 2025) sobre os modelos open-source de alta qualidade do DeepSeek, uma vontade de explorar modelos LLM self-hosted infectou minha mente.
Portanto, decidi construir uma ferramenta de benchmarking com stress test usando Go (Channels 💙), disparar contra Ollama & DeepSeek, monitorar um monte de métricas e compartilhar os resultados com você.
Este post analisa a capacidade de throughput do modelo DeepSeek-R1-Distill-Qwen-7B rodando no Ollama, no meu MacBook de desenvolvimento pessoal, um M2 Pro com 16GB de Ram e uma GPU de 19 Cores.

Ah, o projeto é open source e pode ser encontrado em ocodista/benchmark-deepseek-r1-7b no GitHub (deixe uma ⭐ se você acha que este tipo de conteúdo é útil 😁✌️).
Qual é o objetivo?
Eu queria ver quantas requisições paralelas meu M2 consegue lidar com uma velocidade decente e experimentar com Go + Cursor + Claude Sonnet 3.5.
Foi uma ótima experiência e embora a maioria do código tenha sido escrito por IA, nada da documentação (ou deste texto) foi.
Você pode esperar que este experimento responda as seguintes perguntas:
- Quantos tokens/s posso obter rodando DeepSeek R1 Gwen 7B localmente com ollama?
- Quantas requisições paralelas posso servir com throughput razoável?
- O que é um throughput razoável?
- Como o número de requisições concorrentes impacta o throughput?
- Quanta energia minha GPU usou enquanto rodava este estudo?
Agora vamos falar sobre o teste.
O Prompt
Inspirado por um livro recente que li (A Universe From Nothing), selecionei a seguinte questão como prompt para cada requisição:
Que é uma questão muito profunda que requer algum raciocínio. É útil para analisar o processo de Chain of Thought do DeepSeek R1, já que é uma característica central do modelo retornar a resposta em 2 etapas:
<think>{THINK}</think> e {RESPONSE}.
O que é Tempo?
Tempo tem definições abstratas (o fim final, o primeiro começo) e estruturadas (segundos, minutos, horas).
Pode ser usado para expressar uma relação entre eventos não relacionados, para representar algo que sentimos (a passagem do tempo) quando acessamos nossas memórias, e para refletir sobre os grandes mistérios do universo: De onde viemos? Para onde vamos?

A representação estruturada de tempo selecionada foi min:segundos e vamos analisar Tempo de Espera e Tempo de Duração.
A Resposta
Aqui você pode ver uma das respostas geradas pelo modelo 7B durante um dos testes.
Minha opinião (como Engenheiro de Software, não como filósofo nem físico) é que é muito boa.
É maravilhoso ler a seção <think> e observar como o modelo agrupa múltiplos assuntos relacionados à questão antes de fornecer uma resposta final.
Não sou especialista em Data Science, então não posso explicar os funcionamentos internos, mas parece reutilizar esta primeira exploração do prompt para re-prompting o modelo.
Isso é revolucionário, pois é a primeira vez que vejo essa estratégia de resposta em duas etapas construída dentro do modelo.
A estratégia em si não é necessariamente nova, pois já a usei manualmente antes com um Custom GPT chamado Prompt Optimizer, uma espécie de pré-prompting para obter prompts finais melhores, é especialmente útil ao gerar imagens a partir de texto.
De qualquer forma, isso é muito legal!
A diferença de qualidade entre DeepSeek R1 (modelo completo) e ChatGPT para prompts pequenos é notável.
Esta expansão automática do universo de contexto também elimina a necessidade crescente de ser bom em Prompt Engineering. Agora vem de graça, dentro do modelo.
Então, voltando ao teste 😁
Se você não se importa com como os dados foram coletados, você pode viajar no tempo para os Resultados do Benchmark e ver alguns gráficos bonitos.
Como as métricas foram coletadas?
A ideia era executar múltiplas rodadas de requisições HTTP paralelas para o endpoint do Servidor Web Ollama (1, 2, 4, 8, 16, 19, 32, 38, 57, 64, 76, 95, 128 e 256).
Como minha GPU tem 19 cores, selecionei 19 como uma das rodadas (e alguns outros múltiplos) para garantir que cada Core da GPU estivesse ocupado.

Diagrama de Sequência
O teste vai em ciclos, cada ciclo contendo um conjunto diferente de requisições concorrentes.
Cada ciclo aguarda 10s após terminar para iniciar o próximo.
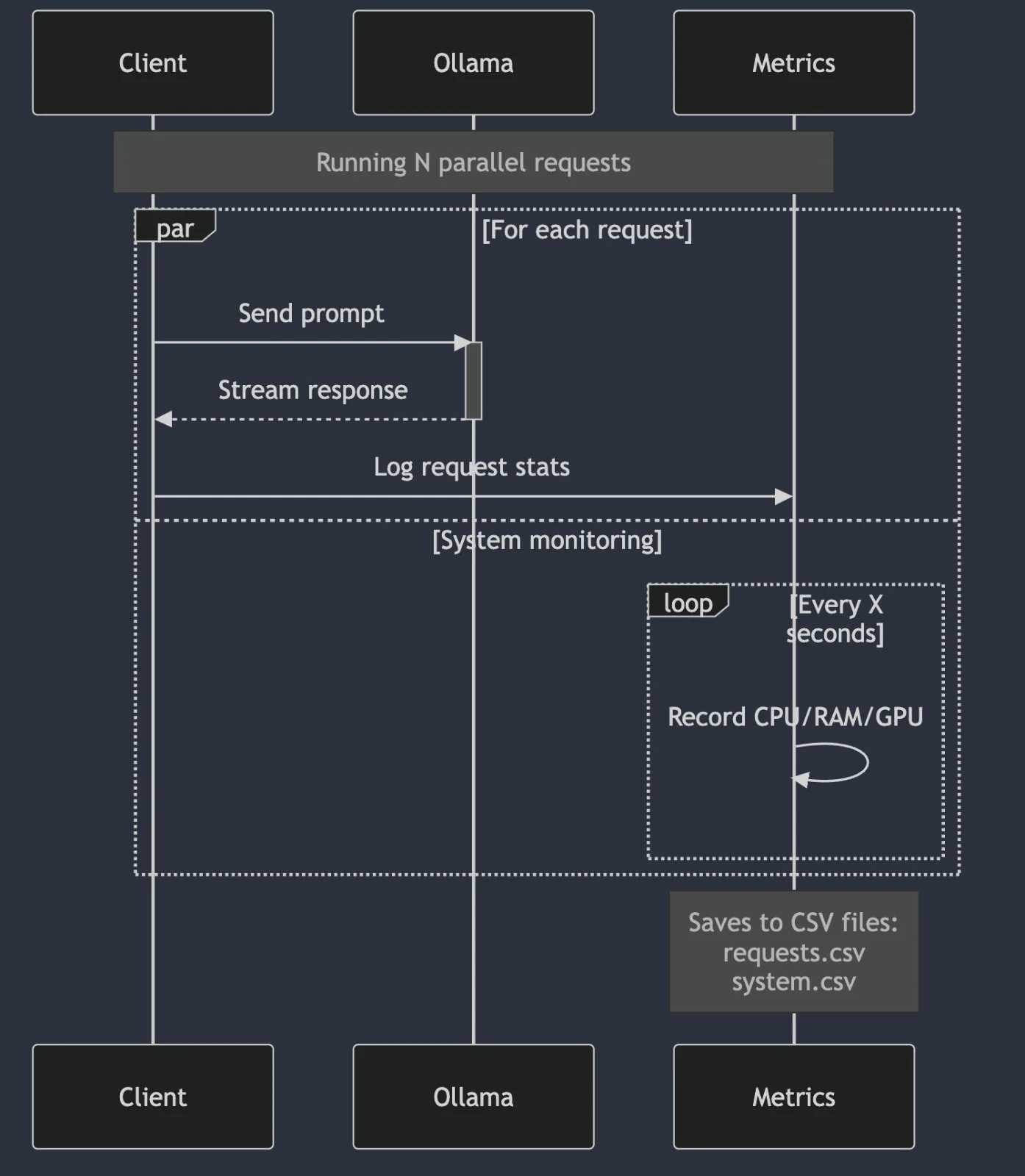
Monitor de Processos
Ele usa pgrep ollama para encontrar todos os PIDs envolvidos na execução das requisições do modelo e vai monitorar, armazenar e exibir:
- Thread Count
- File Descriptors
- RAM Usage
- CPU Usage
Monitor de GPU
Ele usa a incrível ferramenta powermetrics para calcular:
- Power (W)
- Frequency (MHz)
- Usage (%)
Em intervalos de 1s.
Métricas de Requisições
Para cada requisição do ciclo, foram analisadas as seguintes propriedades:
- Throughput (Tokens/s)
- TTFB (Time To First Byte)
- WaitingTime
- TokenCount
- ResponseDuration
- TotalDuration
Especificação de Hardware
| Componente | Especificação |
|---|---|
| Device | MacBook Pro 16-inch (M2, 2023) |
| CPU | 12-core ARM-Based Processor |
| Memory | 16GB RAM |
| GPU | Integrated M2 Series GPU (19 Cores) |
| OS | MacOS Sonoma |
Ferramentas
Ollama
Uma framework CLI de inferência LLM local que é muito fácil de usar.
Para este benchmark, o modelo selecionado foi deepseek-r1:7b, mas poderia ter sido qualquer outro, já que ollama torna ridiculamente simples rodar LLMs localmente.
Golang
A linguagem de programação escolhida, usada para criar o cliente de benchmarking e ferramentas de monitoramento.
Por quê? Bem, Go é uma ferramenta excelente para computação paralela.
Sou um desenvolvedor JS (ainda não sou especialista em Golang), mas consigo reconhecer uma ótima ferramenta paralela/concorrente quando vejo uma.
O Go Scheduler é realmente incrível.
Python
Não há nada melhor que Python para analisar um monte de arquivos CSV e gerar gráficos bonitos.
Para instruções sobre como executar este benchmark, por favor confira how-to-run.md.
Resultados do Benchmark
Como estamos usando requisições HTTP como método de tráfego deste experimento, decidi usar Time To First Byte para representar o Tempo de Espera.
Tempo de Espera (TTFB)
O tempo de espera (TTFB) é o atraso entre apertar a tecla Enter e ver o primeiro caractere na tela.
Como neste experimento o client e o server estão na mesma rede, hardware e computador, estamos na verdade calculando o tempo que leva para o processo Golang se comunicar com o processo Ollama, que vai rodar o modelo DeepSeek R1, que vai gerar as respostas e fazer stream de volta para o processo Golang.
Dito isso, vamos contemplar alguns gráficos coloridos:
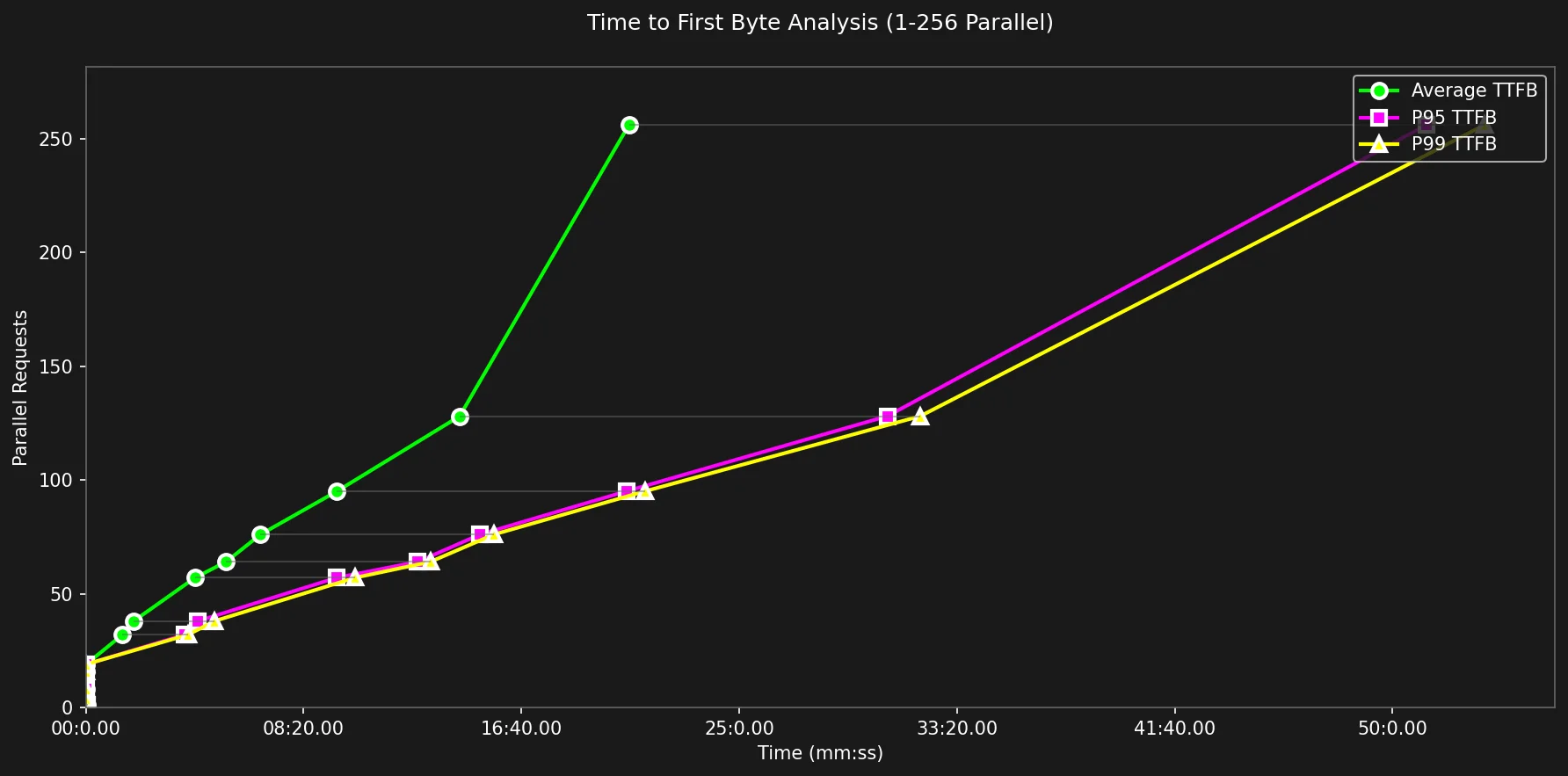
Ok, parece interessante, mostra que em algum lugar perto de 25 requisições paralelas o Tempo de Espera dispara agressivamente e continua a crescer em uma taxa estável, atingindo incríveis 50 minutos no p99 para 256 requisições/s.
Vamos dar zoom:
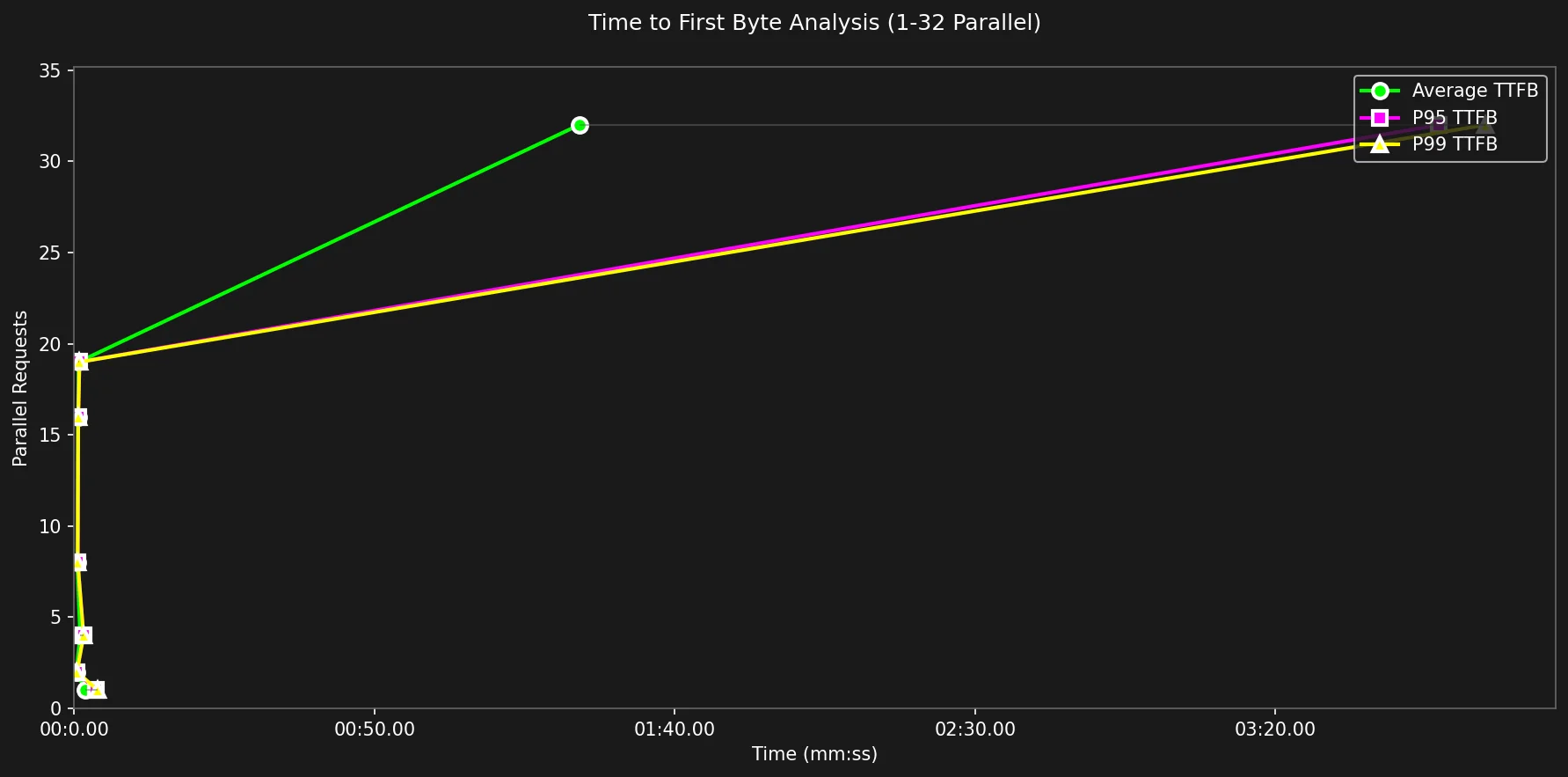
Podemos ver que do ciclo 1-19, o TTFB está próximo de 0, variando sua média de 0.62s a 0.83s, isso é praticamente instantâneo para percepção humana.
Faz sentido se você levar em consideração a quantidade disponível de cores da GPU, o que você deveria, caso contrário a flag OLLAMA_MAX_PARALLEL terá seu valor padrão (4), e seus resultados serão envenenados (confie em mim, já estive lá).
Tabela de Dados TTFB
{% details Tabela de Dados TTFB (apenas se você se importa) %}
| Parallel | Avg | P95 | P99 |
|---|---|---|---|
| 1 | 0.83 | 0.93 | 0.93 |
| 2 | 0.36 | 0.44 | 0.44 |
| 4 | 0.38 | 0.42 | 0.42 |
| 8 | 0.47 | 0.51 | 0.51 |
| 16 | 0.64 | 0.67 | 0.67 |
| 19 | 0.62 | 0.64 | 0.64 |
| 32 | 84.05 | 227.13 | 234.90 |
| 64 | 321.96 | 761.89 | 790.82 |
| 128 | 858.27 | 1839.99 | 1915.72 |
| 256 | 1247.02 | 3078.62 | 3211.85 |
{% enddetails %}
Velocidade
Esta é a métrica mais importante do experimento.
O gráfico seguinte mostra que ao rodar DeepSeek R1 Gwen 7b, self-hosted com Ollama em um MacBook Pro M2 com 16GB de RAM e 19 cores de GPU, podemos atingir um máximo de 55 tokens/s ao fazer uma única requisição.
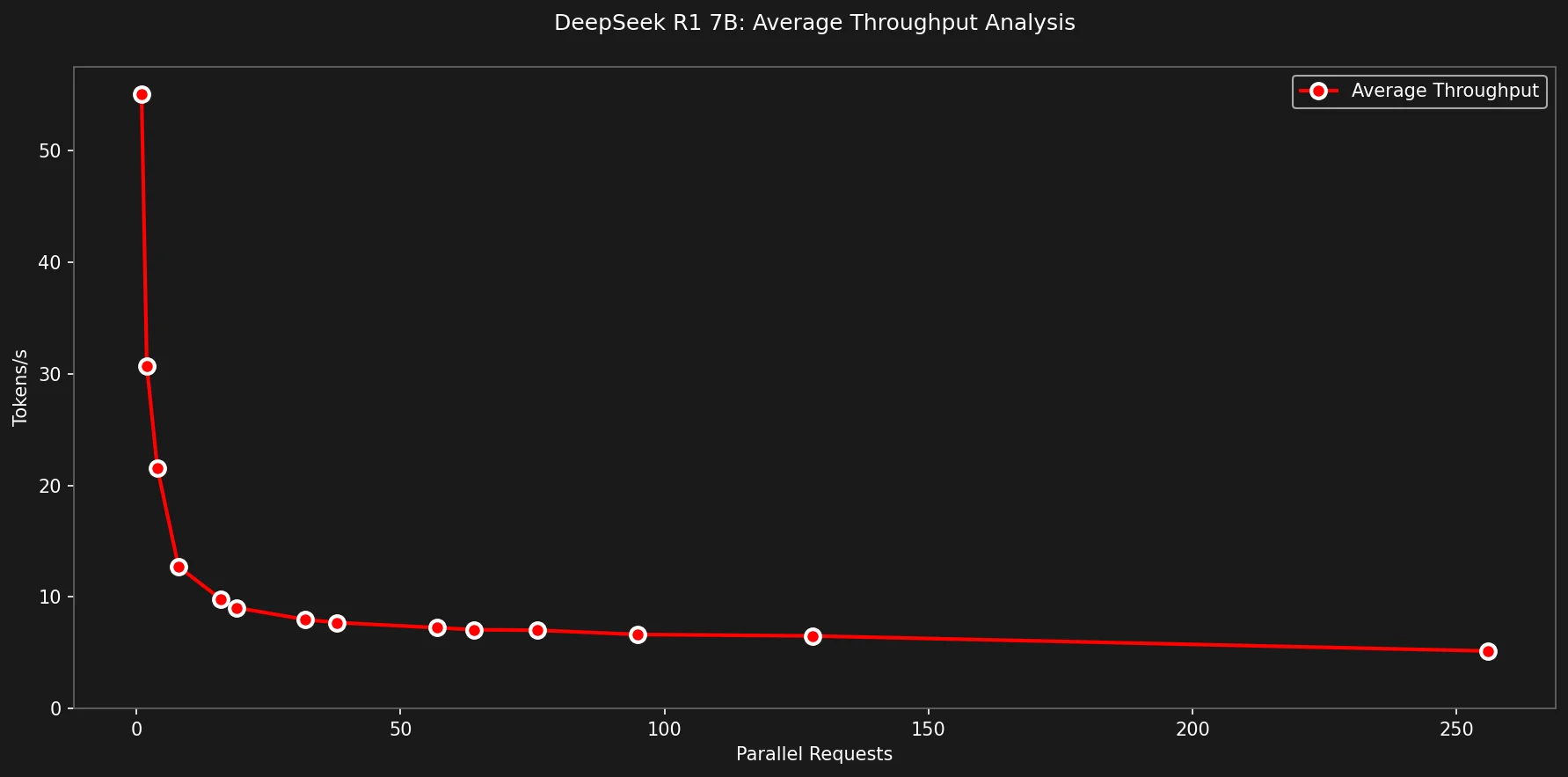
Ao utilizar todo o potencial da GPU com 19 requisições paralelas, porém, o throughput médio caiu para meros 9.1 tokens/s.
Continuou caindo até o menor valor em 256 requisições com 6.3 tokens/s.
Comparando diferentes velocidades de token/s
É difícil visualizar mentalmente o que 55, 9.1 ou 6.3 tokens/s realmente significam, então gravei alguns GIFs para ajudar:
55 tokens por segundo

30.7 tokens por segundo

9.1 tokens por segundo

Para mim, a velocidade ideal de uma aplicação rápida seria em torno de 100 tokens/s, e o limite inferior lento-mas-usável seria em torno de 20 tokens/s. Quero dizer, velocidade mais rápida nunca é suficiente. É como download/upload de internet ou FPS de vídeo (Frames Por Segundo) ao renderizar jogos, quanto maior, melhor.
100 tokens/s

Limiares Aceitáveis
Quais deveriam ser os limiares aceitáveis para uma aplicação do mundo real usável usando DeepSeek + Ollama?
Quanto tempo um usuário médio espera em uma aplicação carregando antes de sair?
Qual é a velocidade aceitável mais lenta para ler um texto sem ficar entediado?
Tempo Máximo de Espera Aceitável
Vou escolher 10s como um valor arbitrário para o tempo máximo de espera aceitável.
Na realidade, os usuários são mais impacientes e o valor pode ser muito menor.
Olhando para os dados da tabela TTFB, 19 é o último ciclo que atende nosso limite de 10s com uma espera de 0.62s. Em 32 requisições paralelas, o Tempo de Espera médio pula para 1 minuto e 25 segundos.
A menos que você esteja usando DeepSeek para tarefas em background sem interação humana, um tempo de espera de 1m25s é inaceitável. Baseado no limite de 10s, o máximo de requisições paralelas para uma aplicação usável deveria ser 19.
Velocidade Mínima de Resposta Aceitável
Acredito que deveria ser ~19.9 tokens/s.
Esta métrica é totalmente arbitrária e pessoalmente escolhida baseada em como me senti assistindo os gifs de velocidade.
Qualquer coisa menos que 20 tokens/s parece levemente irritante.
Com este novo limite, o máximo de requisições paralelas considerando tempo de resposta aceitável é 4.
Ok, vamos dar uma olhada nas métricas combinadas agora.
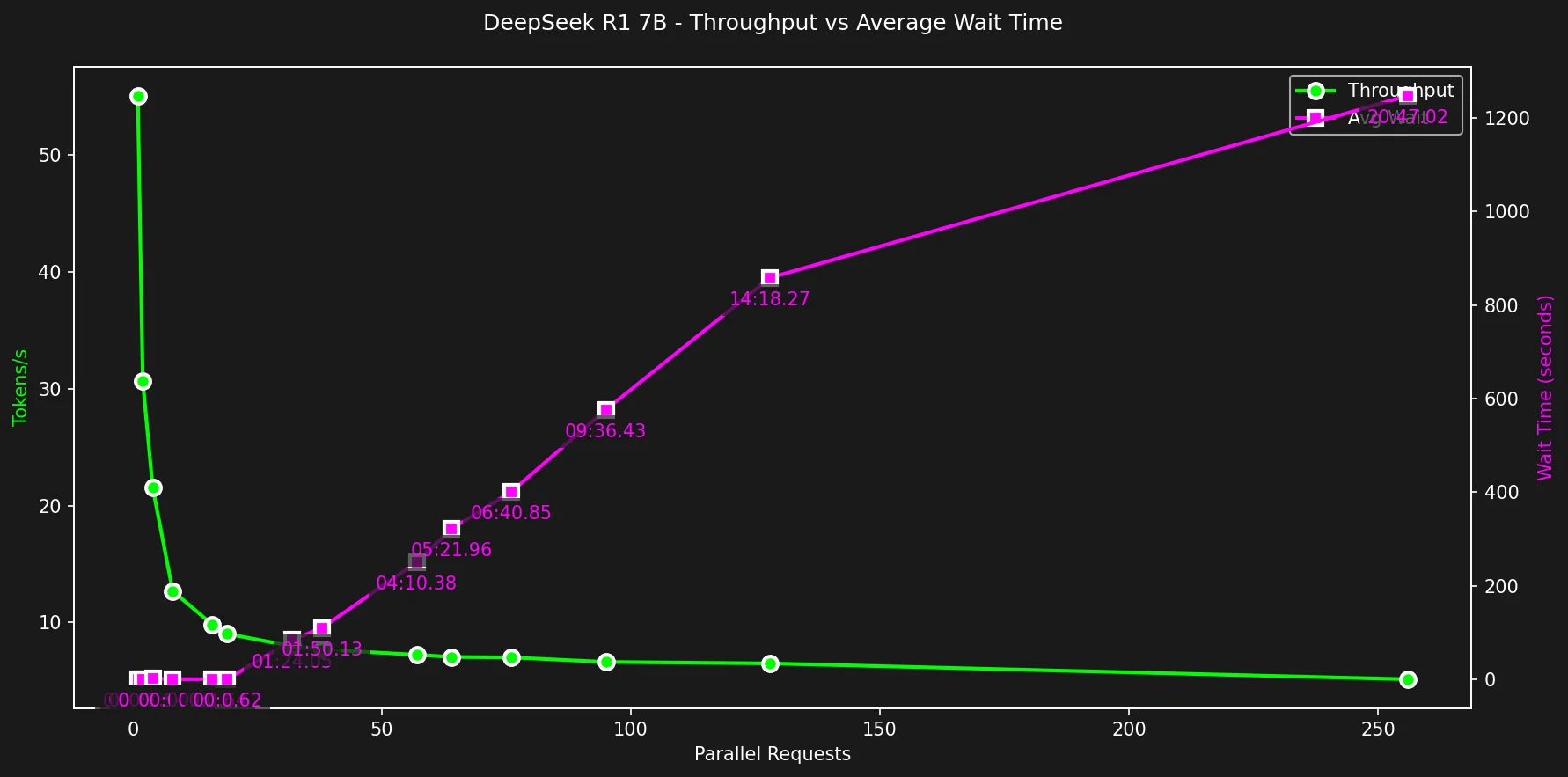
Throughput + Tempo de Espera
Velocidade é boa, mas em 2025, Time To First Byte deve ser mínimo para que um produto seja usável.
Ninguém gosta de clicar em um botão e esperar 20 segundos ou 2 minutos para algo acontecer.
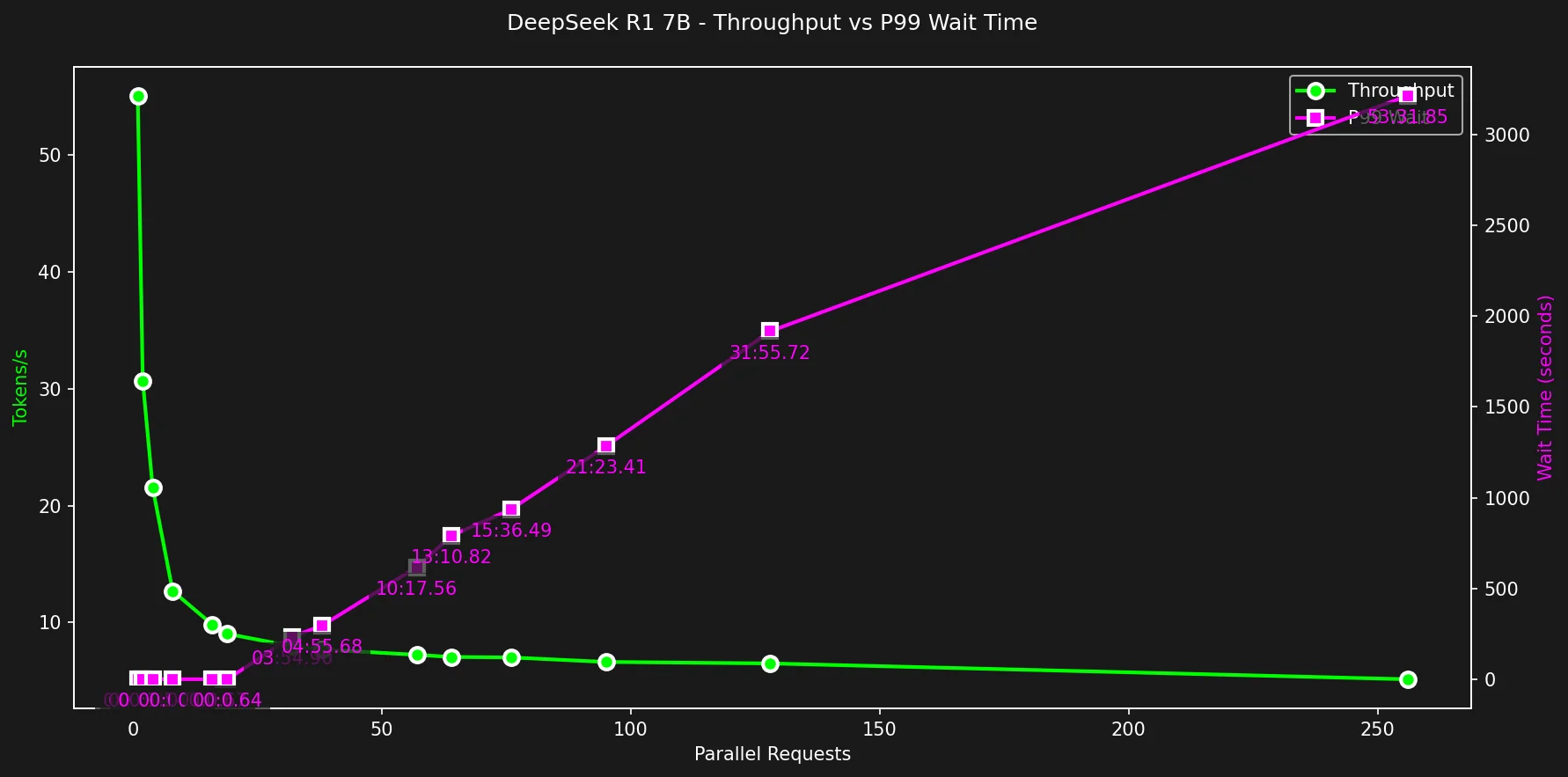
Tabela de Dados Throughput + Tempo de Espera
{% details Tabela de Dados %}
| Parallel | Avg t/s | P95 t/s | P99 t/s | Wait(s) | Errors% | Duration | P99 Duration |
|---|---|---|---|---|---|---|---|
| 1.0 | 53.1 | 53.1 | 53.1 | 0.94 | 0.0 | 00:39.33 | 00:39.33 |
| 2.0 | 30.7 | 30.9 | 30.9 | 0.36 | 0.0 | 01:12.09 | 01:12.27 |
| 4.0 | 19.9 | 20.4 | 20.5 | 1.54 | 0.0 | 01:34.31 | 01:47.17 |
| 5.0 | 19.2 | 20.6 | 20.7 | 0.30 | 0.0 | 01:39.01 | 01:59.26 |
| 8.0 | 12.9 | 13.5 | 13.7 | 0.47 | 0.0 | 02:32.12 | 02:54.62 |
| 16.0 | 9.8 | 10.1 | 10.3 | 0.64 | 0.0 | 03:26.81 | 04:41.07 |
| 19.0 | 9.1 | 9.5 | 9.6 | 0.62 | 0.0 | 03:43.55 | 05:23.83 |
| 32.0 | 8.0 | 9.3 | 9.3 | 84.05 | 0.0 | 04:08.64 | 06:15.66 |
| 64.0 | 7.1 | 9.0 | 9.3 | 321.96 | 0.0 | 04:39.51 | 07:30.13 |
| 128.0 | 6.5 | 8.9 | 9.2 | 858.27 | 0.0 | 05:06.60 | 07:28.05 |
| 256.0 | 6.3 | 8.8 | 9.4 | 1534.79 | 0.0 | 04:12.89 | 07:52.97 |
{% enddetails %}
Duração
O primeiro ciclo durou menos de um minuto (39 segundos) enquanto o último ciclo levou 8 min e 51 segundos para completar.
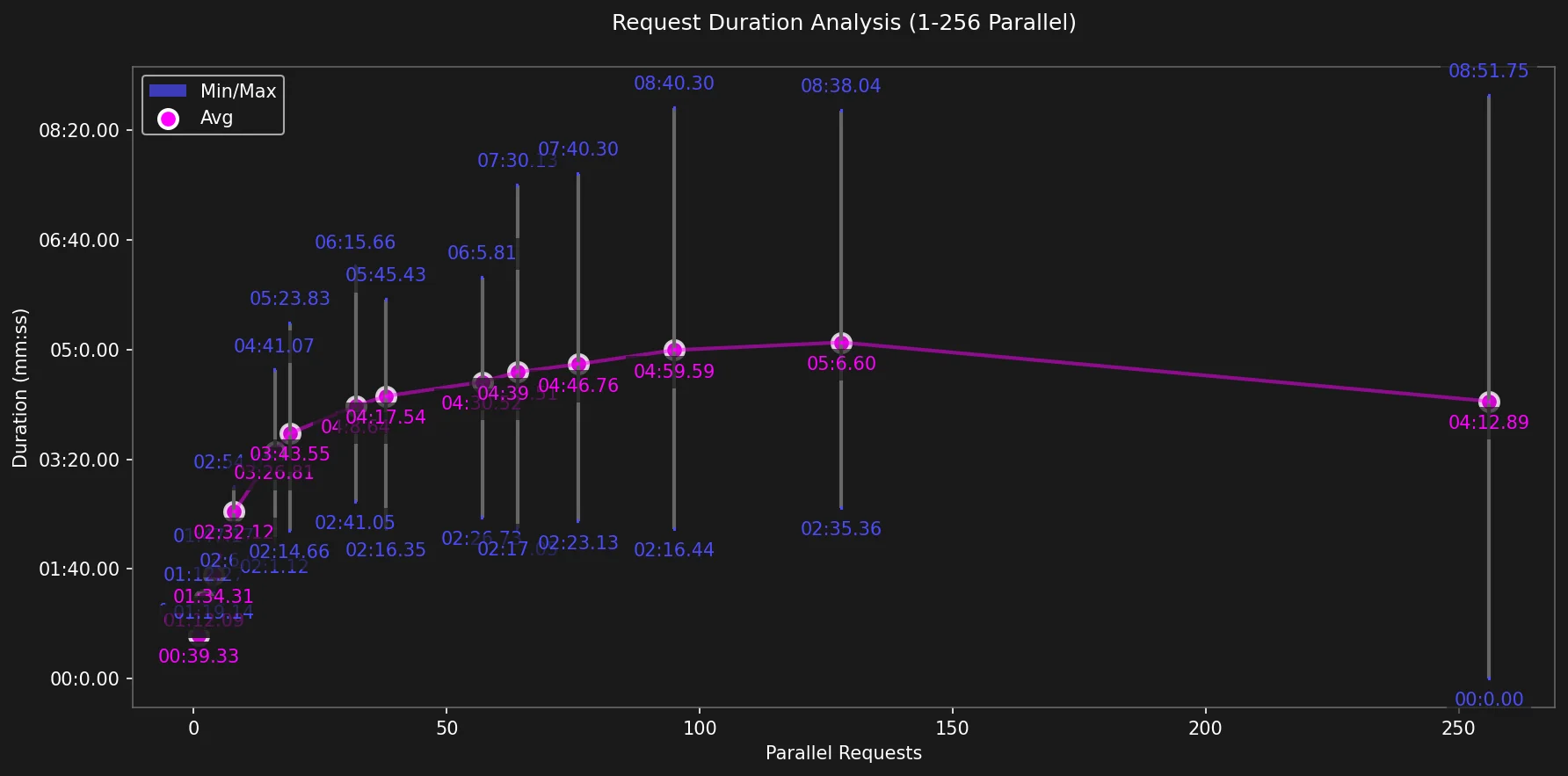
Duração Média das Requisições
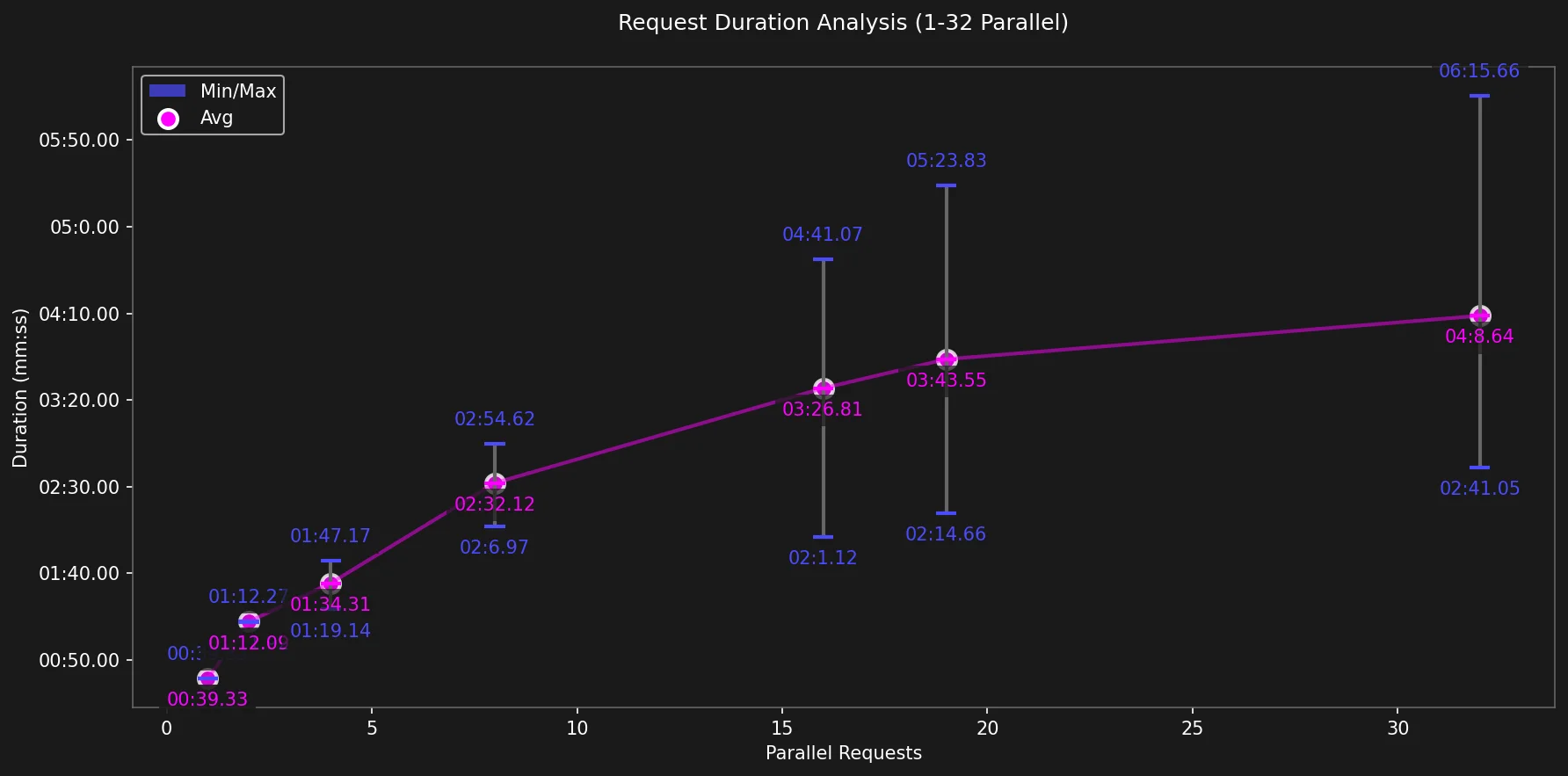
Para os ciclos iniciais, a duração média de cada requisição cresce lentamente mas notavelmente. Enquanto a requisição única levou apenas 39s para completar, requisições que usaram todos os cores disponíveis (ciclo 19) levaram, em média, 03 minutos e 43 segundos para completar.
{% details Tabela de Dados %}
| Parallel | Min | Avg | P99 | Max |
|---|---|---|---|---|
| 1 | 00:39.33 | 00:39.33 | 00:39.33 | 00:39.33 |
| 2 | 01:11.92 | 01:12.09 | 01:12.27 | 01:12.27 |
| 4 | 01:19.14 | 01:34.31 | 01:47.17 | 01:47.17 |
| 5 | 01:24.99 | 01:39.01 | 01:59.26 | 01:59.26 |
| 8 | 02:06.97 | 02:32.12 | 02:54.62 | 02:54.62 |
| 16 | 02:01.12 | 03:26.81 | 04:41.07 | 04:41.07 |
| 19 | 02:14.66 | 03:43.55 | 05:23.83 | 05:23.83 |
| 32 | 02:41.05 | 04:08.64 | 06:15.66 | 06:15.66 |
| 64 | 02:17.05 | 04:39.51 | 07:30.13 | 07:30.13 |
| 128 | 02:35.36 | 05:06.60 | 07:28.05 | 08:38.04 |
| 256 | 00:00.00 | 04:12.89 | 07:52.97 | 08:51.75 |
{% enddetails %}
Métricas Combinadas (Tokens/s x Duração x Tempo de Espera)
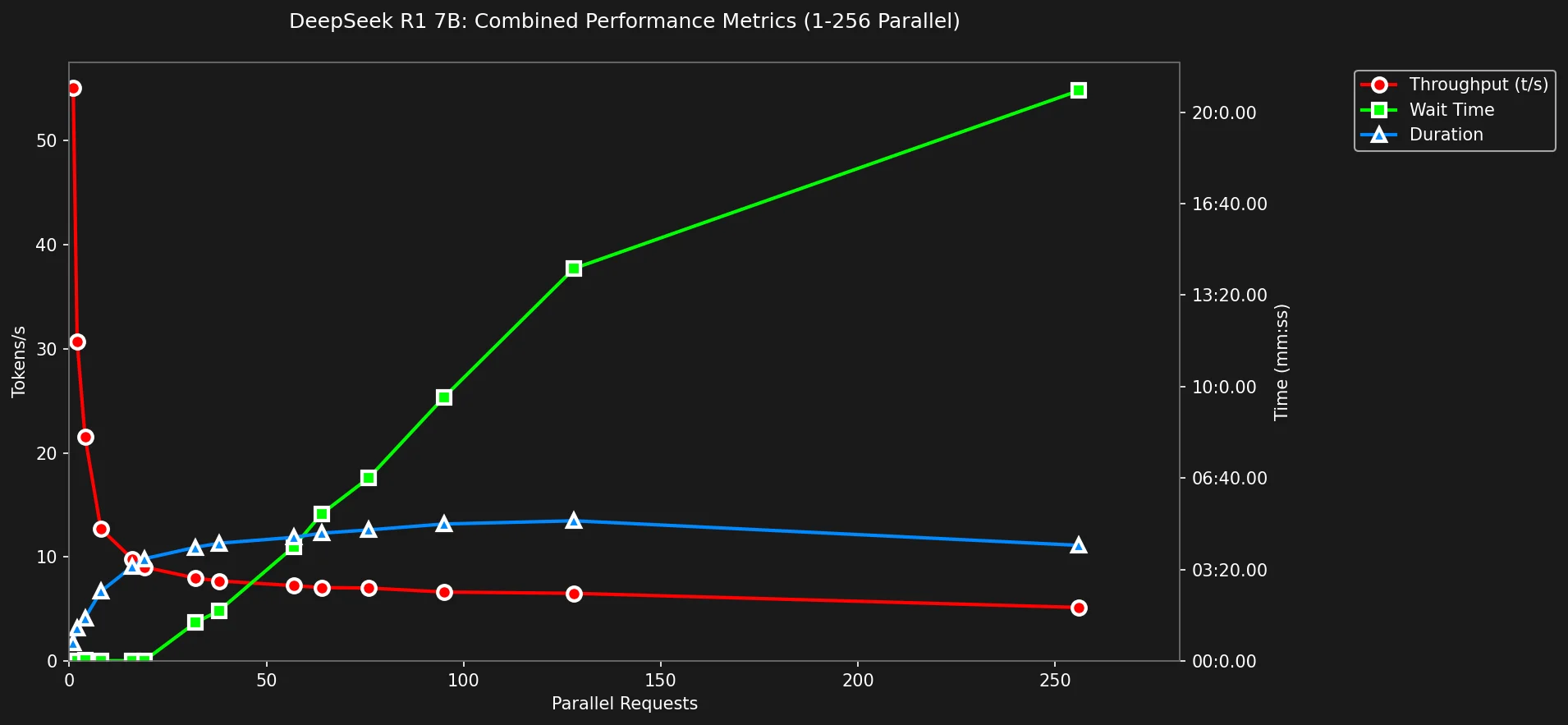
O tempo de espera cresce linearmente após 19 requisições paralelas, tornando-o inutilizável para aplicações interativas.
Também mostra que o throughput cai exponencialmente antes de estabilizar em ciclos muito menores.
Vamos dar zoom em ciclos menores:
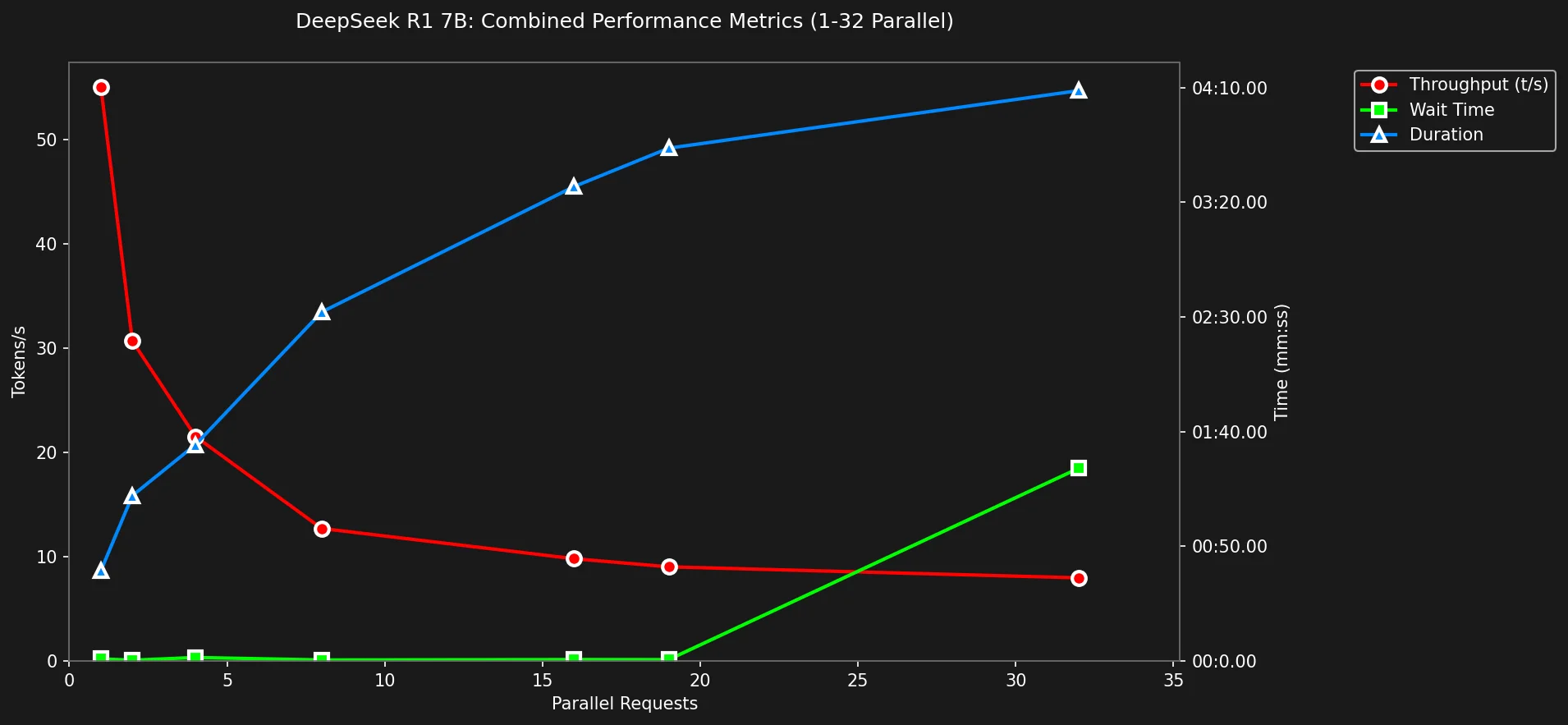
Aqui, o gráfico é diferente: o tempo de espera é estável em <1s até o ciclo 19 e é claro ver a conexão entre throughput e duração de requisição p99.
Uso de GPU
Graças ao powermetrics, é possível obter métricas de uso de GPU no MacOS!
O Macbook M2 de 19-GPU provou ser bastante constante, com pequenas variações na Frequência da GPU, estável em 1397MHz, e Uso de Energia, estável em ~20.3W.
O nível de concorrência não pareceu afetar as métricas da GPU.
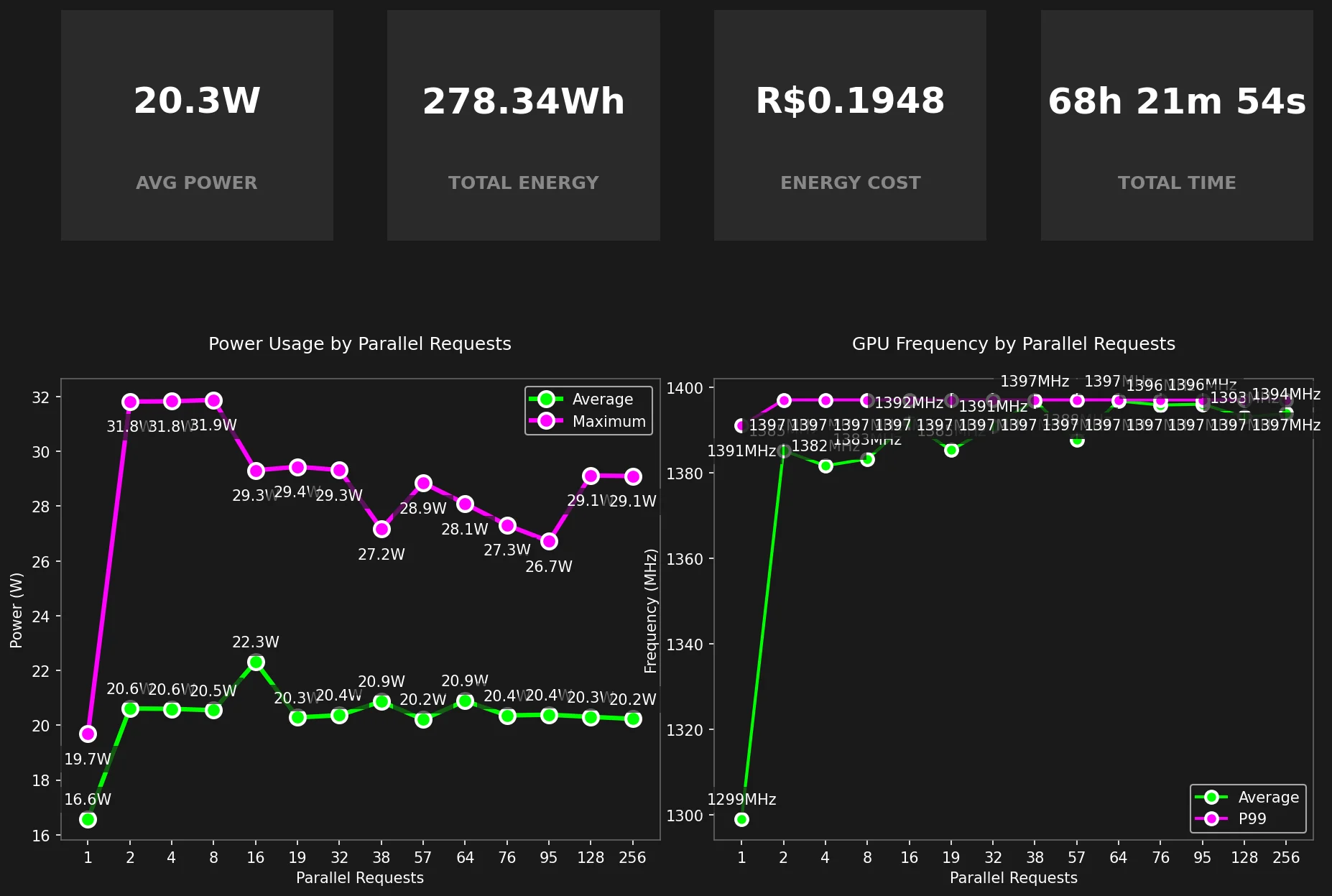
sudo powermetrics --samplers gpu_power -n1 -i1000Uso de RAM/CPU/Threads
Para analisar quanto recurso do computador o Ollama + DeepSeek estava consumindo, rastreei os processos ollama (com pgrep, lsof e ps) e monitorei as seguintes métricas:
- CPU Usage (%)
- Memory Usage (%)
- Resident Memory (MB)
- Thread Count (int)
- File Descriptors (int)
- Virtual Memory Size (MB)
Ok, quando você tem ollama serve rodando ocioso, ele usa um único processo.
Quando há 1 ou 256 requisições ativas, ollama usa 2 processos.
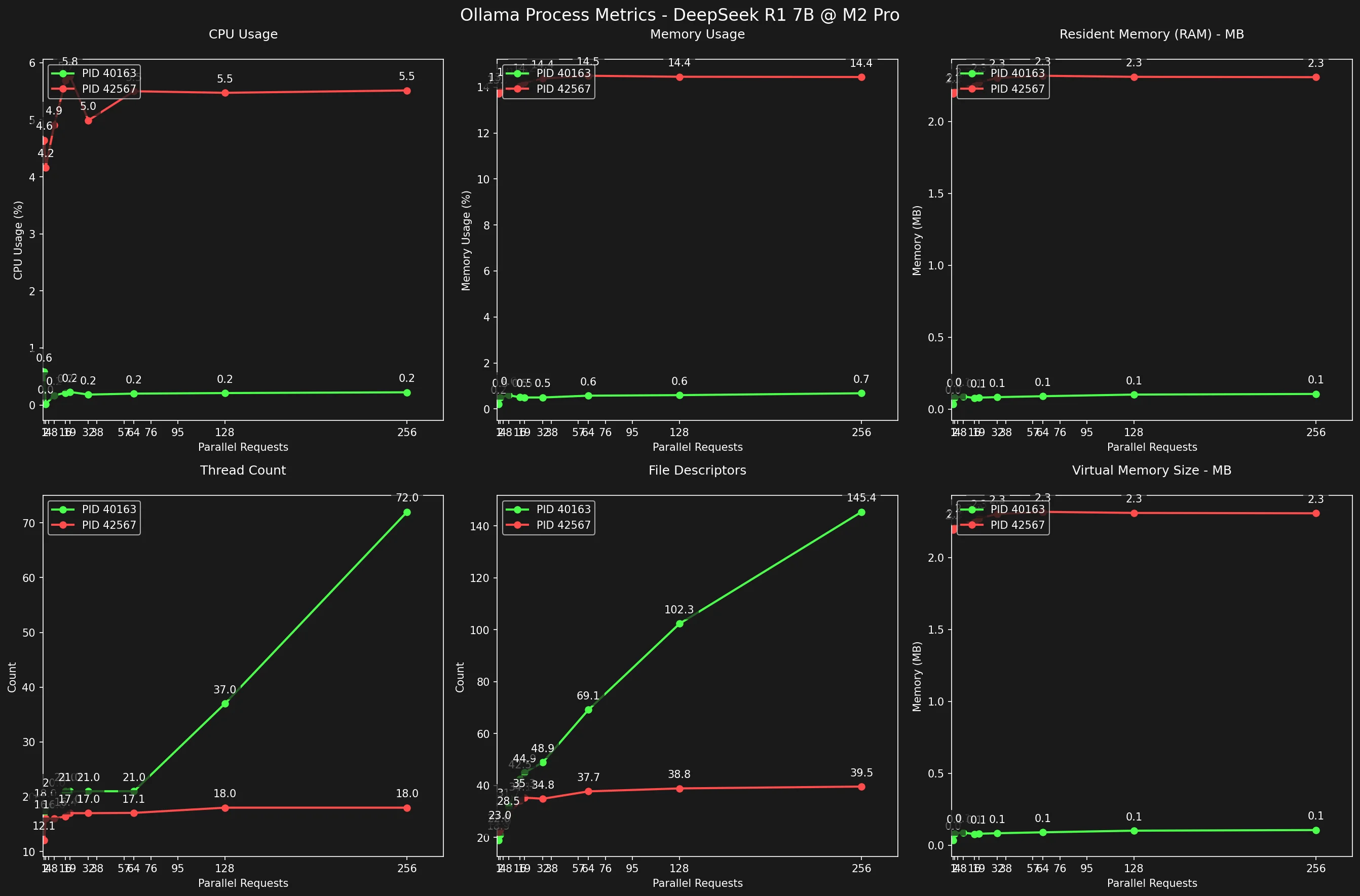
Ao analisar o gráfico, podemos ver que eles se comportam diferentemente um do outro.
Enquanto um deles tem alto uso de memória/cpu e baixa contagem de threads/descritores de arquivo abertos, o outro tem o oposto: baixo uso de cpu/memória com FDs abertos crescendo linearmente e alta contagem de threads.
Se eu tivesse que adivinhar, diria que o processo verde pode ser responsável pelo Servidor Web enquanto o vermelho pelo LLM DeepSeek R1.
Processo do Servidor Web
Enquanto os File Descriptors abertos crescem linearmente conforme o número de requisições concorrentes cresce, a contagem de Threads tem um padrão mais íngreme para cima.
Notavelmente, o uso de CPU e memória deste processo permanecem constantemente baixos, entre 0.2~0.6% para CPU e 82.6 -> 114.1MB para RAM.
{% details Tabela de Dados %}
| Concurrency | Avg CPU% | Max CPU% | Avg Mem% | Max Mem% | Avg Threads | Avg FDs | Avg RAM(MB) | Max RAM(MB) |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.6 | 22.8 | 0.2 | 0.5 | 17.0 | 18.9 | 36.4 | 82.6 |
| 2 | 0.0 | 0.8 | 0.5 | 0.5 | 18.0 | 21.0 | 83.4 | 83.6 |
| 8 | 0.2 | 1.7 | 0.6 | 0.6 | 20.0 | 31.7 | 90.4 | 90.9 |
| 16 | 0.2 | 1.5 | 0.5 | 0.6 | 21.0 | 42.5 | 79.4 | 95.2 |
| 19 | 0.2 | 2.2 | 0.5 | 0.5 | 21.0 | 44.9 | 82.0 | 82.6 |
| 32 | 0.2 | 2.2 | 0.5 | 0.5 | 21.0 | 48.9 | 85.6 | 86.2 |
| 64 | 0.2 | 2.9 | 0.6 | 0.6 | 21.0 | 69.1 | 92.1 | 94.6 |
| 128 | 0.2 | 2.7 | 0.6 | 0.7 | 37.0 | 102.3 | 103.8 | 108.4 |
| 256 | 0.2 | 4.2 | 0.7 | 0.7 | 72.0 | 145.4 | 108.2 | 114.1 |
{% enddetails %}
Processo do DeepSeek
Se os FDs Abertos e a Contagem de Threads delataram o processo do Servidor Web, o Consumo de Memória e a contagem máxima de Threads de 18 delataram o Processo do DeepSeek.
O fato de o número de threads não ultrapassar o número de Cores da GPU, mesmo sob ciclo de concorrência mais alto, indica que este processo pode ser o responsável pelo DeepSeek, que usa a GPU, que tem 19 cores.
O uso médio de RAM deste processo é notável: de 2.2 a 2.3GB, representando 13.7 a 14.6% de toda RAM disponível, o uso de CPU também é alto para um processo, consumindo 5.7% para uma única requisição e 13.1% para 256.
{% details Tabela de Dados %}
| Concurrency | Avg CPU% | Max CPU% | Avg Mem% | Max Mem% | Avg Threads | Avg FDs | Avg RAM(MB) | Max RAM(MB) |
|---|---|---|---|---|---|---|---|---|
| 1 | 4.6 | 5.7 | 13.7 | 13.7 | 12.1 | 22.0 | 2248.1 | 2250.6 |
| 2 | 4.2 | 5.2 | 13.8 | 13.8 | 16.0 | 23.0 | 2259.9 | 2263.1 |
| 8 | 4.9 | 7.9 | 14.0 | 14.1 | 16.0 | 28.5 | 2299.6 | 2303.3 |
| 16 | 5.7 | 11.6 | 14.0 | 14.3 | 16.4 | 34.1 | 2299.1 | 2335.5 |
| 19 | 5.8 | 14.3 | 14.2 | 14.2 | 17.0 | 35.3 | 2327.4 | 2330.6 |
| 32 | 5.0 | 12.0 | 14.4 | 14.4 | 17.0 | 34.8 | 2359.1 | 2366.3 |
| 64 | 5.5 | 14.2 | 14.5 | 14.6 | 17.1 | 37.7 | 2374.2 | 2390.0 |
| 128 | 5.5 | 13.2 | 14.4 | 14.6 | 18.0 | 38.8 | 2366.5 | 2397.7 |
| 256 | 5.5 | 13.1 | 14.4 | 14.6 | 18.0 | 39.5 | 2364.1 | 2385.5 |
{% enddetails %}
Resultados Resumidos
Estes resultados foram gerados rodando Ollama + DeepSeek em um Macbook M2 Pro, 16GB de RAM e GPU de 19-Core, provavelmente será diferente em uma configuração diferente.
Quantos tokens/s posso obter rodando DeepSeek R1 Gwen 7B localmente com ollama?
Para uma única requisição: 53.1 tokens/s.
Para 19 requisições paralelas -> 9.1 tokens/s.
Para 256 requisições concorrentes -> 6.3 tokens/s.
Você pode conferir os Dados da Tabela se quiser.
Quantas requisições paralelas posso servir com throughput razoável?
Assumindo 19.9 tokens/s como um throughput razoável, esta máquina pode servir até 4 requisições em paralelo.
Isso pode ser suficiente para tarefas de rotina diária de uma única pessoa, mas definitivamente não é suficiente para rodar um servidor de API comercial.
O que é um throughput razoável?
Durante o curso da escrita deste artigo, criei uma CLI para mostrar diferentes velocidades de token/s, você pode conferir aqui.
Como o número de requisições concorrentes impacta a performance?
Muito!
Para mais de 19 requisições concorrentes, o tempo de espera se torna insuportável, e para mais de 5 requisições paralelas, a velocidade de resposta é muito baixa.
Conclusão
Considerando que esta é a versão do modelo 7b, e pode atingir até 55 tokens/s ao servir uma única requisição, eu diria que é rápido e bom o suficiente para conversar interativamente durante tarefas diárias, com um uso de energia razoavelmente baixo (mesmo que uma lâmpada de led).
Quero dizer, a qualidade está longe de ser ótima quando comparada à versão 671b (que é o modelo que supera os modelos OpenAI), mas acredito que isso é apenas o começo.
Estratégias de quantização se tornarão mais efetivas, e em breve seremos capazes de escolher assuntos para treinar modelos menores, que demonstramos ser possível rodar no computador de um desenvolvedor. É possível, estamos na Indústria de Tecnologia.
Aconteceu com o processador, o disco e a memória, é questão de tempo até acontecer com chips de inferência de IA e modelos LLM.
É isso por hoje, obrigado pela leitura 😁✌️!