
Olá!
Neste post, vou fazer um teste de estresse em uma API Node.js 21.2.0 pura (sem framework!) para ver a eficiência do Event Loop em um ambiente limitado.
Estou usando AWS para hospedar os servidores (EC2) e banco de dados (RDS com Postgres).
O objetivo principal é entender quantas requisições por segundo uma API Node simples pode lidar em um único core, então identificar o gargalo e otimizá-lo o máximo possível.
Vamos mergulhar!
Infraestrutura
- AWS RDS rodando Postgres
- EC2 t2.small para a API
- EC2 t3.micro para o load tester
Configuração do Banco de Dados
O banco de dados consistirá de uma única tabela users criada com a seguinte query SQL:
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
email VARCHAR(255) NOT NULL,
password VARCHAR(255) NOT NULL
);
TRUNCATE TABLE users;Design da API
A API terá um único endpoint POST que será usado para salvar um usuário no banco de dados Postgres. Eu sei, existem muitos frameworks javascript por aí que eu poderia usar para tornar o desenvolvimento mais fácil, mas é possível usar apenas Node para lidar com as requisições/respostas.
Para conectar ao banco de dados, escolhi a biblioteca pg pois é a mais popular, vamos começar com ela.
Connection Pooling
Uma coisa que é importante ao conectar a um banco de dados é usar um connection pool. Sem um connection pool, a API precisa abrir/fechar uma conexão ao banco de dados em cada requisição, o que é extremamente ineficiente.
Um pool permite que a API reutilize conexões, já que estamos planejando enviar muitas requisições concorrentes para nossa API, é crucial tê-lo.
Para verificar o limite de conexões do seu banco de dados Postgres, execute:
SHOW max_connections;No meu caso, estou usando um RDS rodando em um banco de dados t3.micro com estas especificações:
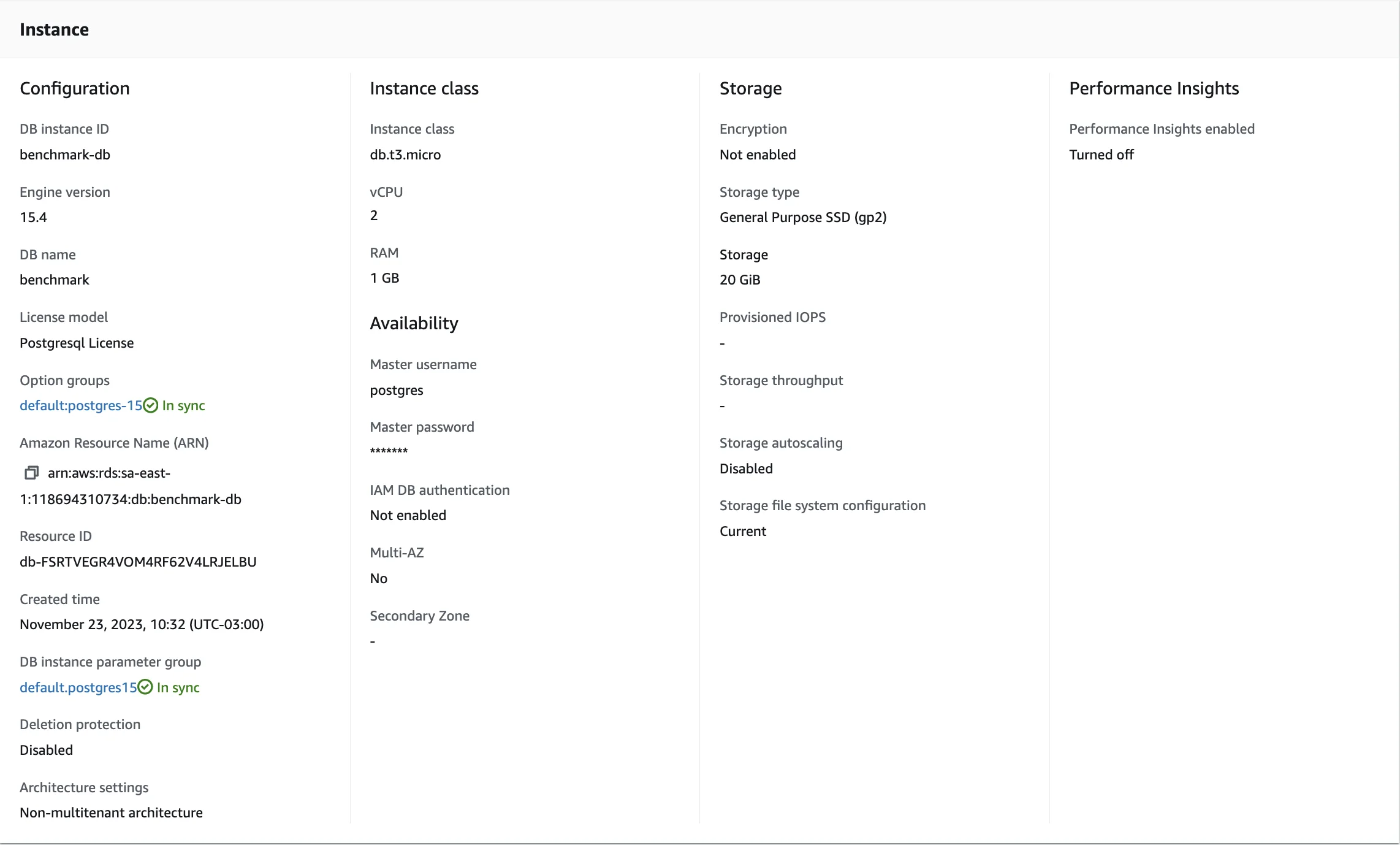
Então este é o resultado da query:
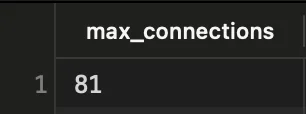
Legal, tendo 81 como o número máximo de conexões ao nosso banco de dados, sabemos qual é o limite superior que não devemos ultrapassar.
Como a API rodará em um processador de single-core, não é uma boa ideia ter um alto número de conexões no connection pool, pois isso causaria muita dor de cabeça para o processador (context switching).
Vamos começar com 40.
Criando a API
Vamos começar iniciando nosso projeto com npm init e criando nosso arquivo index.mjs. MJS para que eu possa usar sintaxe EcmaScript sem fazer muita mágica/parsing/loading.
A primeira coisa que vou fazer é adicionar a biblioteca pg com npm add pg. Estou usando npm, mas você pode usar pnpm, yarn ou qualquer outro gerenciador de pacotes node que quiser.
Então, vamos começar criando nosso connection pool:
import pg from "pg"; // Necessário porque a lib pg usa CommonJS 🤢
const { Pool } = pg;
const pool = new Pool({
host: process.env.POSTGRES_HOST,
user: process.env.POSTGRES_USER,
password: process.env.POSTGRES_PASSWORD,
port: 5432,
database: process.env.POSTGRES_DATABASE,
max: 40, // Limite é 81, vamos começar com 40
idleTimeoutMillis: 0, // Quanto tempo antes de expulsar um cliente ocioso.
connectionTimeoutMillis: 0, // Quanto tempo para desconectar um novo cliente, não queremos desconectá-los por enquanto.
ssl: false
/* Se você estiver rodando na AWS, você precisará usar:
ssl: {
rejectUnauthorized: false
}
*/
});Estamos usando process.env para acessar as variáveis de ambiente, então crie um arquivo .env na raiz e preencha com suas informações do postgres:
POSTGRES_HOST=
POSTGRES_USER=
POSTGRES_PASSWORD=
POSTGRES_DATABASE=Então, vamos criar uma função para persistir nosso usuário no banco de dados.
const createUser = async (email, password) => {
const queryText =
"INSERT INTO users(email, password) VALUES($1, $2) RETURNING id";
const { rows } = await pool.query(queryText, [email, password]);
return rows[0].id;
};Finalmente, vamos criar um servidor HTTP node importando o pacote node:http e escrevendo um código para lidar com novas requisições, fazer parse de string para JSON, consultar o banco de dados e retornar 201, 400 ou 500 em caso de quaisquer erros, o arquivo final fica assim.
// index.mjs
import http from "node:http";
import pg from "pg";
const { Pool } = pg;
const pool = new Pool({
host: process.env.POSTGRES_HOST,
user: process.env.POSTGRES_USER,
password: process.env.POSTGRES_PASSWORD,
port: 5432,
database: process.env.POSTGRES_DATABASE,
max: 40,
idleTimeoutMillis: 0,
connectionTimeoutMillis: 2000,
ssl: false
/* Se você estiver rodando na AWS, você precisará usar:
ssl: {
rejectUnauthorized: false
}
*/
});
const createUser = async (email, password) => {
const queryText =
"INSERT INTO users(email, password) VALUES($1, $2) RETURNING id";
const { rows } = await pool.query(queryText, [email, password]);
return rows[0].id;
};
const getRequestBody = (req) =>
new Promise((resolve, reject) => {
let body = "";
req.on("data", (chunk) => (body += chunk.toString()));
req.on("end", () => resolve(body));
req.on("error", (err) => reject(err));
});
const sendResponse = (res, statusCode, headers, body) => {
headers["Content-Length"] = Buffer.byteLength(body).toString();
res.writeHead(statusCode, headers);
res.end(body);
};
const server = http.createServer(async (req, res) => {
const headers = {
"Content-Type": "application/json",
Connection: "keep-alive", // Padrão para keep-alive para conexões persistentes
"Cache-Control": "no-store", // Sem caching para criação de usuário
};
if (req.method === "POST" && req.url === "/user") {
try {
const body = await getRequestBody(req);
const { email, password } = JSON.parse(body);
const userId = await createUser(email, password);
headers["Location"] = `/user/${userId}`;
const responseBody = JSON.stringify({ message: "User created" });
sendResponse(res, 201, headers, responseBody);
} catch (error) {
headers["Connection"] = "close";
const responseBody = JSON.stringify({ error: error.message });
console.error(error);
const statusCode = error instanceof SyntaxError ? 400 : 500;
sendResponse(res, statusCode, headers, responseBody);
}
} else {
headers["Content-Type"] = "text/plain";
sendResponse(res, 404, headers, "Not Found!");
}
});
const PORT = process.env.PORT || 3000;
server.listen(PORT, () => {
console.log(`Server running on http://localhost:${PORT}`);
});Agora, após executar npm install, você pode executar
node --env-file=.env index.mjsPara iniciar a aplicação, você deve ver isso no seu terminal:

Parabéns, construímos uma NodeAPI simples com um endpoint que conecta ao Postgres através de um Connection Pool e insere um novo usuário na tabela users.
Fazendo Deploy da API para uma EC2
Primeiro, crie uma conta AWS e vá para EC2 > Instances > Launch an Instance.
Então, crie uma instância Ubuntu 64-bit (x86) t2.micro, permita tráfego SSH e permita tráfego HTTP da Internet.
Seu resumo deve ficar assim:
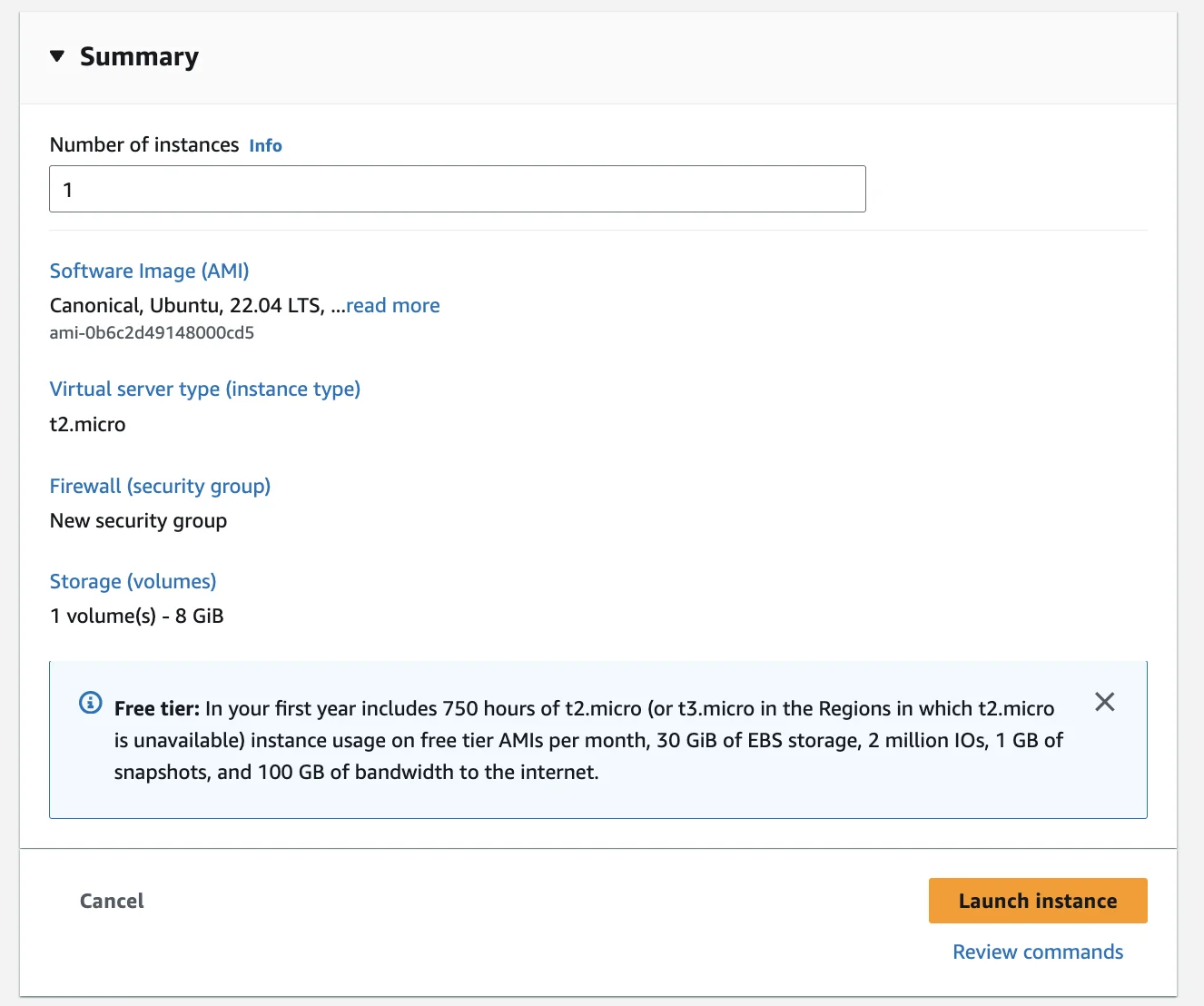
Você precisará criar um arquivo key-value-pair.pem para poder fazer SSH nela, não vou cobrir isso neste artigo, já existem muitos tutoriais ensinando como lançar e conectar a uma instância EC2 na internet, então encontre-os!
Permitindo conexões TCP na porta 3000
Após a criação, precisamos permitir tráfego TCP para a porta 3000, isso é feito na configuração do Security Group (EC2 > Security Groups > Your Security Group)
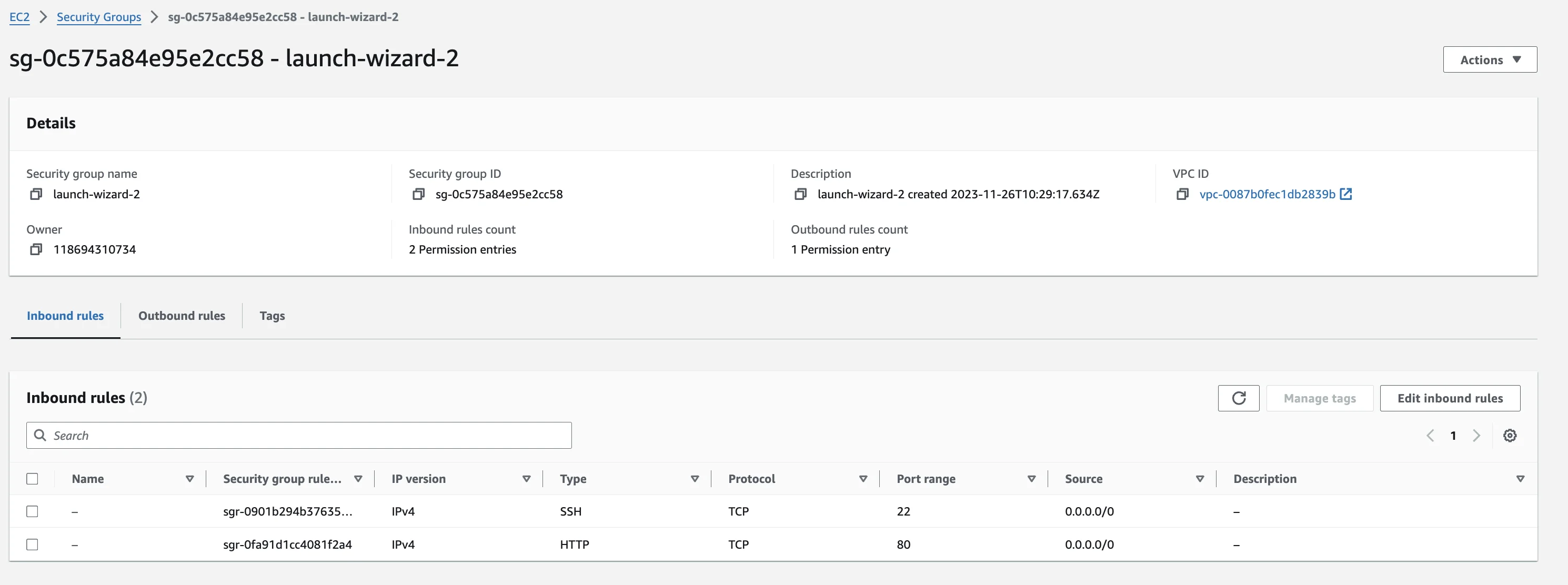
Nesta página, clique em "Edit inbound rules", depois "Add rule" e preencha o formulário conforme mostrado na imagem, isso nos permitirá acessar a porta 3000 da nossa instância.
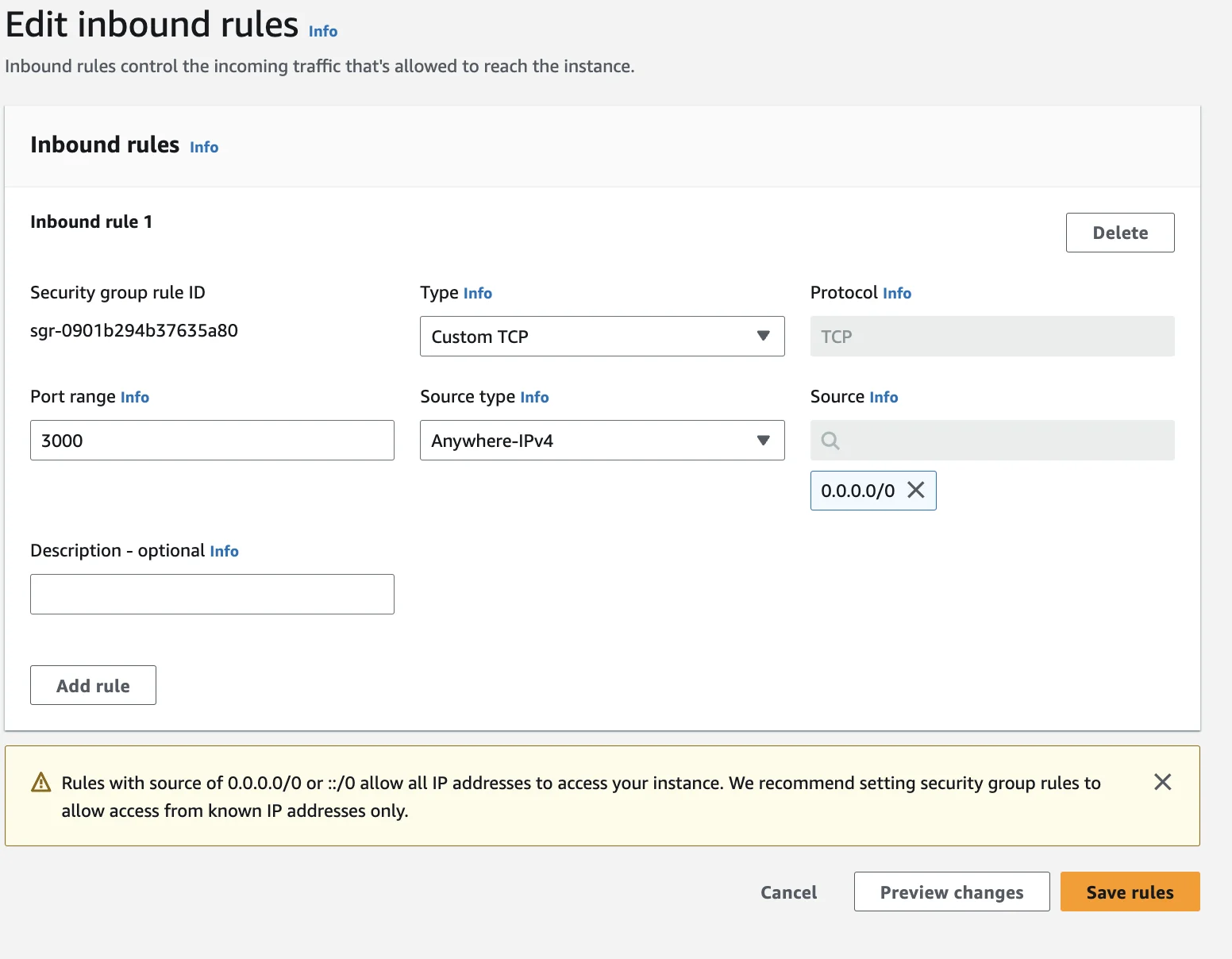
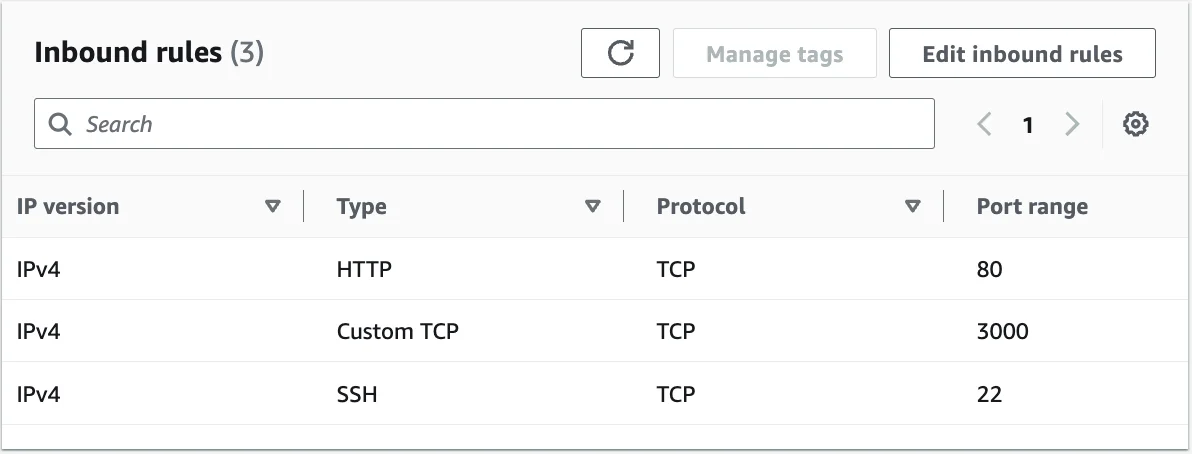
Sua tabela final de Inbound Rules deve ficar parecida com isso.
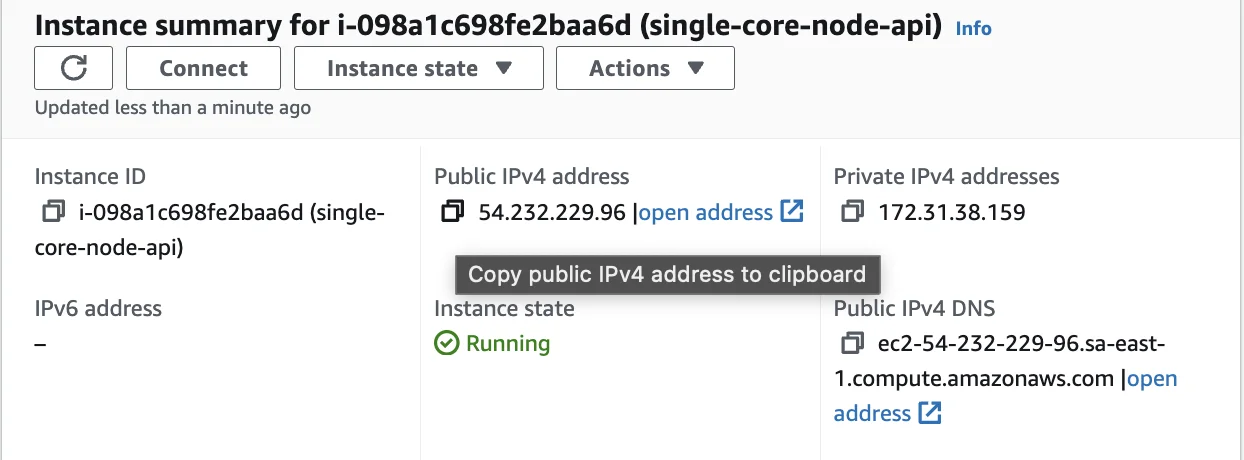
Conectando à EC2
Baixe o arquivo .pem em uma pasta, então acesse a instância EC2 e copie o IP público IPV4, então, execute este comando na mesma pasta:
ssh -i <path-to-pen> ubuntu@<public-ipv4-address>Se você ver esta página de boas-vindas do EC2, então você está dentro 🎉
Instalando Node
Vamos seguir a documentação do Node para distribuições Linux baseadas em Debian/Ubuntu.
Execute:
sudo apt-get update
sudo apt-get install -y ca-certificates curl gnupg
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key | sudo gpg --dearmor -o /etc/apt/keyrings/nodesource.gpgEntão:
NODE_MAJOR=21
echo "deb [signed-by=/etc/apt/keyrings/nodesource.gpg] https://deb.nodesource.com/node_$NODE_MAJOR.x nodistro main" | sudo tee /etc/apt/sources.list.d/nodesource.listImportante: Verifique novamente que o NODE_MAJOR é 21, pois queremos usar a versão mais recente do Node <3
sudo apt-get update
sudo apt-get install nodejs -y
node -vE é isso que você deve ver (pode diferir a versão conforme este post envelhece)

Legal, agora temos um servidor ubuntu novo com node instalado, precisamos transferir nosso código da API para ele e iniciá-lo.
Fazendo Deploy da API para EC2
Vamos usar uma ferramenta chamada scp que usa conexão ssh para copiar arquivo do local para um local de destino, no nosso caso, a instância EC2 que acabamos de criar.
Passos:
- Exclua a pasta node_modules do projeto.
- Vá para a pasta pai da pasta raiz da aplicação.
No meu caso, o nome da pasta é node-api (eu sei, muito criativo!)
Agora, execute:
scp -i <path-to-pem> -r ./node-api ubuntu@<public-ipv4-address>:/home/ubuntuPara transferir a pasta node-api para a pasta /home/ubuntu/node-api na nossa instância EC2.
Você deve ver algo similar a isso:
Executando a API na EC2
Volte para o servidor EC2 usando ssh e execute
cd node-api
npm install
NODE_ENV=production node --env-file=.env index.mjsE boom, a API está rodando na AWS.
Vamos verificar novamente se está funcionando fazendo uma requisição POST passando email e password para o IP da nossa API, na porta 3000.
Você pode usar curl (em outro terminal), para fazer isso:
curl -X POST -H "Content-Type: application/json" -d {email: user@example.com, password: password} http://<public-ipv4-address>:3000/userO resultado deve ficar assim:

Estou usando Table Plus para conectar ao banco de dados RDS Postgres, você poderia usar qualquer Cliente Postgres.
Para garantir que a API está persistindo dados no banco de dados, vamos executar esta query:
SELECT COUNT(id) FROM users;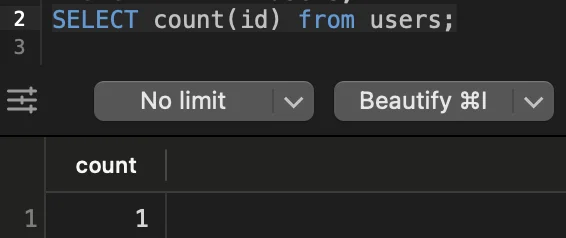
Deve retornar 1.
Legal, está funcionando!
Teste de Estresse
Agora que temos nossa API funcionando, precisamos ser capazes de testar quantas requisições concorrentes ela pode lidar com um único core.
Existem toneladas de ferramentas para fazer isso, vou usar Vegeta
Você pode executar os seguintes passos da sua máquina local, mas tenha em mente que sua rede pode ser o gargalo, já que o teste de estresse requer muitos pacotes serem enviados ao mesmo tempo.
Vou usar outra instância EC2 (uma mais poderosa, t2x.large) rodando Ubuntu.
Configurando Vegeta
Siga a documentação para instalar Vegeta no seu OS.
Então, crie uma nova pasta para load testers na pasta raiz da aplicação, está ficando assim:
node_benchmark/
node-api/
load-tester/
vegeta/Vá para a pasta vegeta e crie um script start.sh com o seguinte conteúdo:
#!/bin/bash
if [[ $# -ne 1 ]]; then
echo 'Wrong arguments, expecting only one (reqs/s)'
exit 1
fi
TARGET_FILE="targets.txt"
DURATION="30s" # Duração do teste, por exemplo, 60s para 60 segundos
RATE=$1 # Número de requisições por segundo
RESULTS_FILE="results_$RATE.bin"
REPORT_FILE="report_$RATE.txt"
ENDPOINT="http://<ipv4-public-address>:3000/user"
# Verificar se Vegeta está instalado
if ! command -v vegeta &> /dev/null
then
echo "Vegeta could not be found, please install it."
exit 1
fi
# Criar arquivo de target com email e password únicos para cada requisição
echo "Generating target file for Vegeta..."
# Assumindo que body.json existe e contém a estrutura JSON correta para a requisição POST
for i in $(seq 1 $RATE); do
echo "POST $ENDPOINT" >> "$TARGET_FILE"
echo "Content-Type: application/json" >> "$TARGET_FILE"
echo "@body.json" >> "$TARGET_FILE"
echo "" >> "$TARGET_FILE"
done
echo "Starting Vegeta attack for $DURATION at $RATE requests per second..."
# Executar o ataque e salvar os resultados em um arquivo binário
vegeta attack -rate=$RATE -duration=$DURATION -targets="$TARGET_FILE" > "$RESULTS_FILE"
echo "Load test finished, generating reports..."
# Gerar um relatório textual do arquivo de resultados binário
vegeta report -type=text "$RESULTS_FILE" > "$REPORT_FILE"
echo "Textual report generated: $REPORT_FILE"
# Gerar um relatório JSON para análise adicional
JSON_REPORT="report.json"
vegeta report -type=json "$RESULTS_FILE" > "$JSON_REPORT"
echo "JSON report generated: $JSON_REPORT"
cat $REPORT_FILEIMPORTANTE: Substitua <ipv4-public-address> pelo IP do seu Servidor de API EC2 Node
Agora, crie um arquivo body.json:
{
"email": "A1391FDC-2B51-4D96-ADA4-5EEE649A4A75@example.com",
"password": "password"
}Agora você está pronto para começar a fazer load-testing da nossa api.
Este script vai:
- Executar por 30s
- Atingir a API com requisições/s concorrentes definidas pelo primeiro argumento do script
- Gerar um arquivo textual e .json com infos sobre o teste.
Por último, mas não menos importante, precisamos tornar o arquivo start.sh executável, podemos fazer isso executando:
chmod +x start.shAntes de executar cada teste, vou limpar a tabela users no Postgres com a seguinte query.
TRUNCATE TABLE users;Isso nos ajudará a ver quantos usuários foram criados!
1.000 Reqs/s
Certo, vamos para a parte interessante, vamos ver se nosso servidor de core único, 1GB pode lidar com 1.000 requisições por segundo.
Execute
./start.sh 1000Espere pela conclusão, aqui gera a seguinte saída:
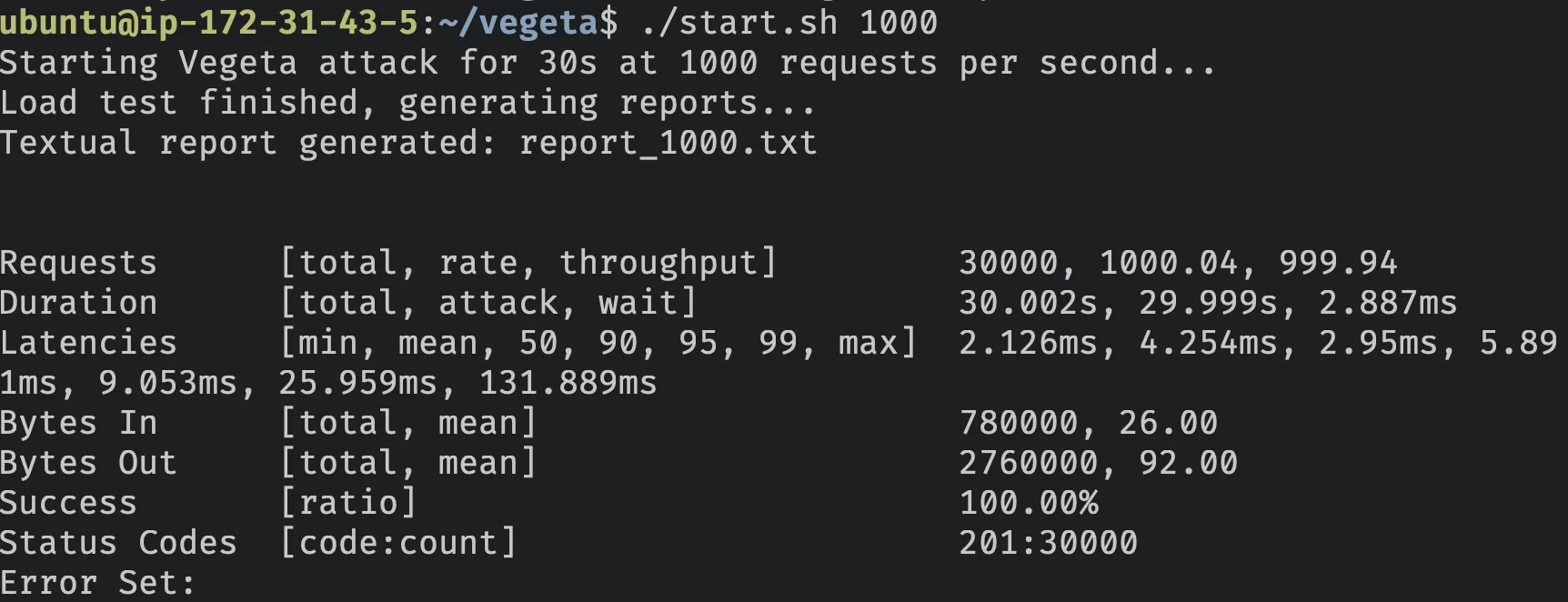
Deixe-me detalhar para você:
Na taxa de 1.000 requisições por segundo, a API Node foi capaz de processar com sucesso todas elas, retornando o status de sucesso esperado 201.
Em média, cada requisição levou 4.254 ms para ser retornada, com 99% delas retornando em menos de 25.959 ms.
| Métrica | Valor |
|---|---|
| Requisições por Segundo | 1000.04 |
| Taxa de Sucesso | 100% |
| Tempo de Resposta p99 | 25.959 ms |
| Tempo de Resposta Médio | 4.254 ms |
| Tempo de Resposta Mais Lento | 131.889 ms |
| Tempo de Resposta Mais Rápido | 2.126 ms |
| Código de Status 201 | 30000 |
Vamos verificar nosso banco de dados:
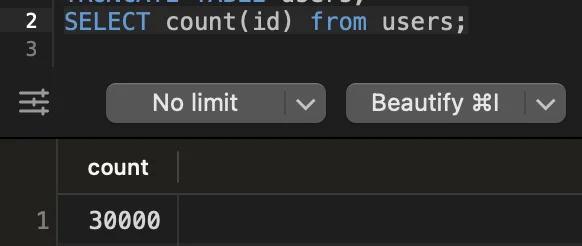
Legal, funcionou!
Vamos tentar mais difícil e dobrar o número de requisições por segundo.
2.000 Requisições por segundo
Execute
./start.sh 2000Vamos verificar a saída
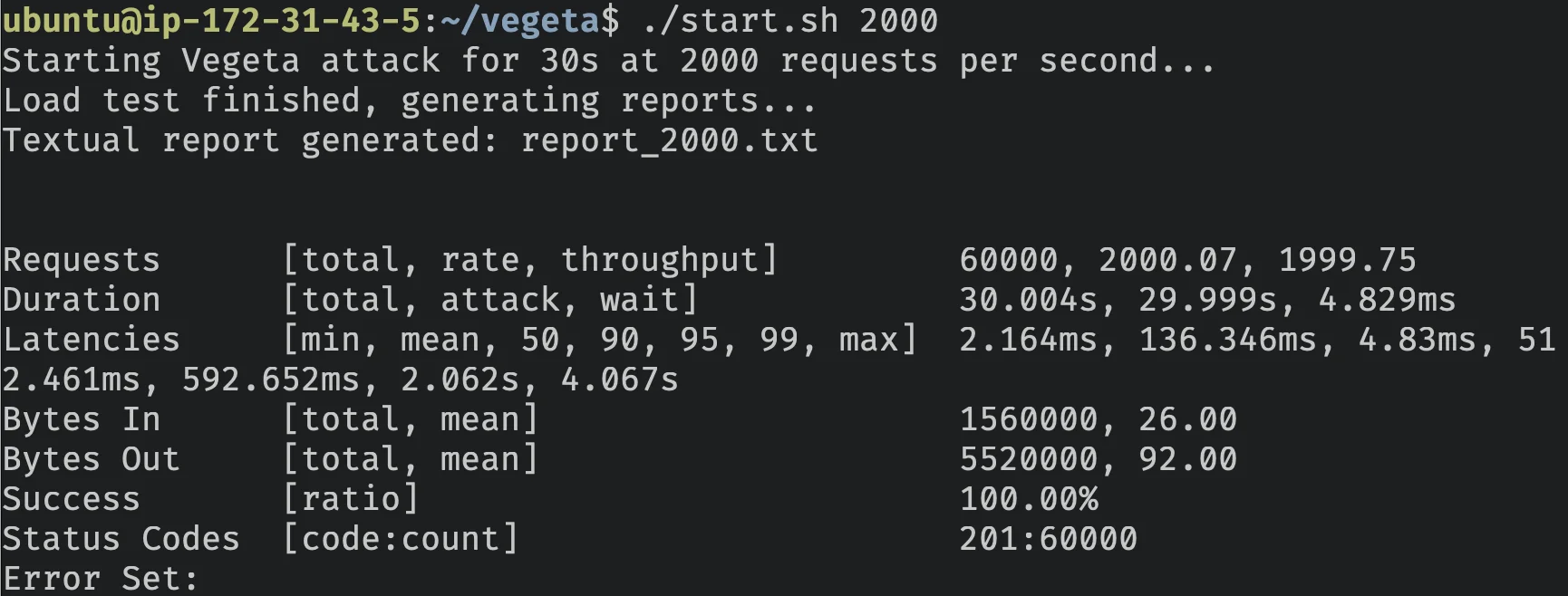
Incrível, pode lidar com 2.000 requisições/segundo e ainda manter uma taxa de sucesso de 100%.
| Métrica | Valor |
|---|---|
| Requisições por Segundo | 2000.07 |
| Taxa de Sucesso | 100.00% |
| Tempo de Resposta p99 | 2.062 s |
| Tempo de Resposta Médio | 136.347 ms |
| Tempo de Resposta Mais Lento | 4.067 s |
| Tempo de Resposta Mais Rápido | 2.164 ms |
| Código de Status 201 | 60000 |
Algumas coisas a notar aqui, enquanto a taxa de sucesso ainda era 100%, o p99 pulou de 25.959ms para 2.067s (79x mais lento que o teste anterior).
O tempo de resposta médio também pulou de 4.254ms para 136.347 (32.1x mais lento).
Então sim, dobrar o número de requisições por segundo está fazendo nosso servidor sofrer MUITO.
Vamos tentar mais difícil e ver o que acontece.
3.000 Requisições por segundo
./start.sh 3000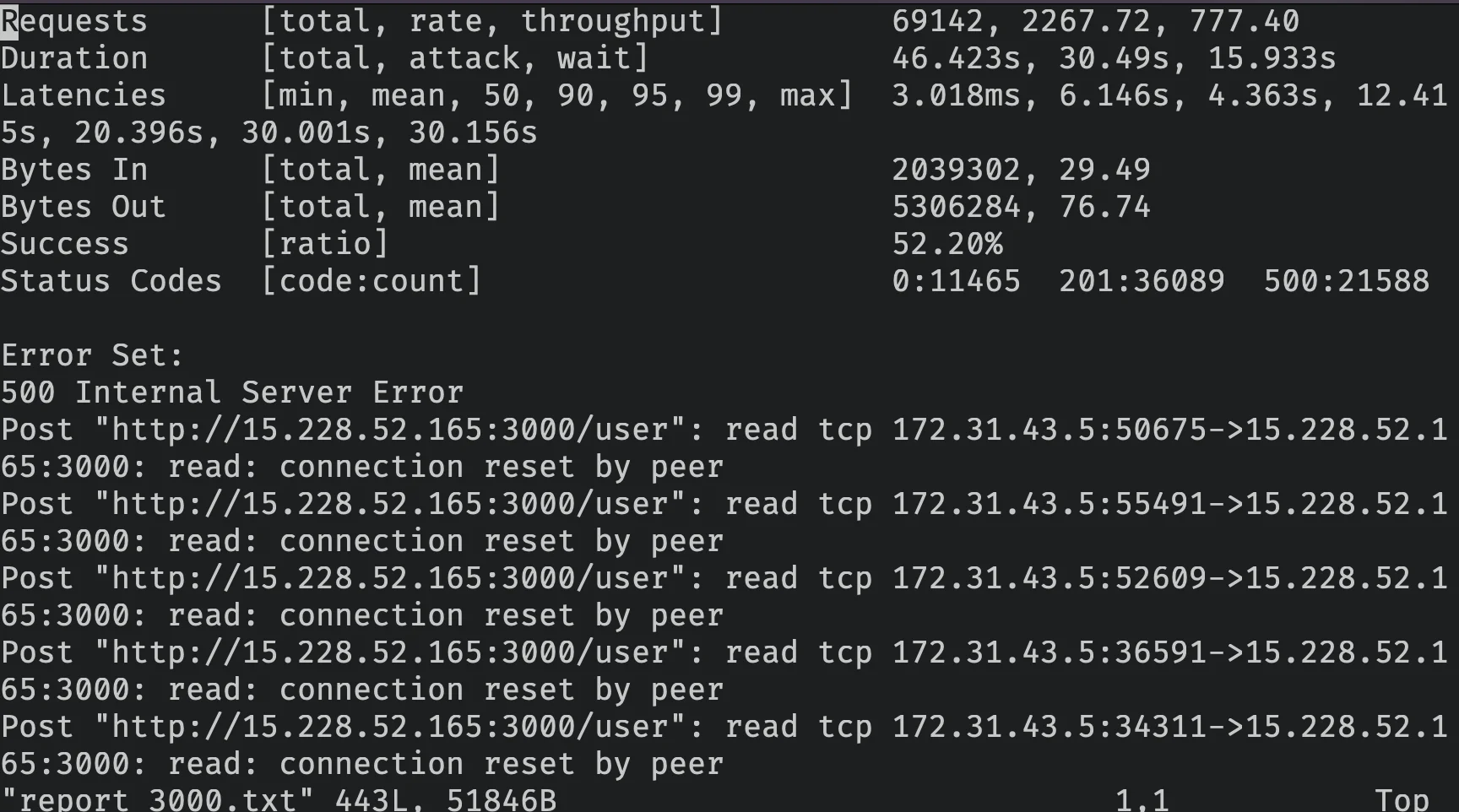
Para 3.000 requisições/segundo nossa API Node.js começou a apresentar problemas, sendo capaz de processar apenas 52.20%, vamos ver o que aconteceu.
| Métrica | Valor |
|---|---|
| Requisições por Segundo | 2267.72 |
| Taxa de Sucesso | 52.20% |
| Tempo de Resposta p99 | 30.001 s |
| Tempo de Resposta Médio | 6.146 s |
| Tempo de Resposta Mais Lento | 30.156 s |
| Tempo de Resposta Mais Rápido | 3.018 ms |
| Código de Status 201 | 36089 |
| Código de Status 500 | 21588 |
| Código de Status 0 | 11465 |
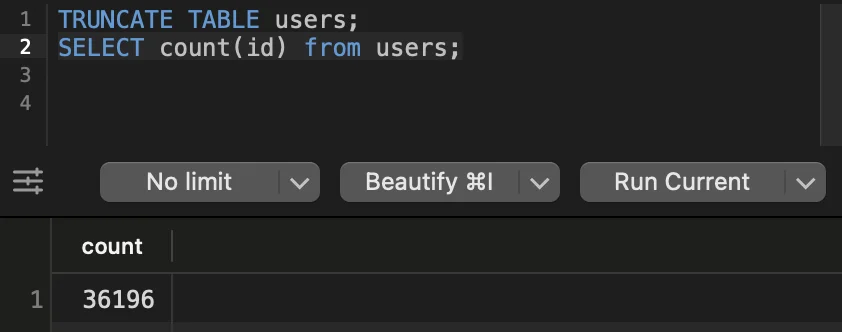
Para 21.588 requisições, nossa API retornou código de status 500, vamos verificar os logs da API:
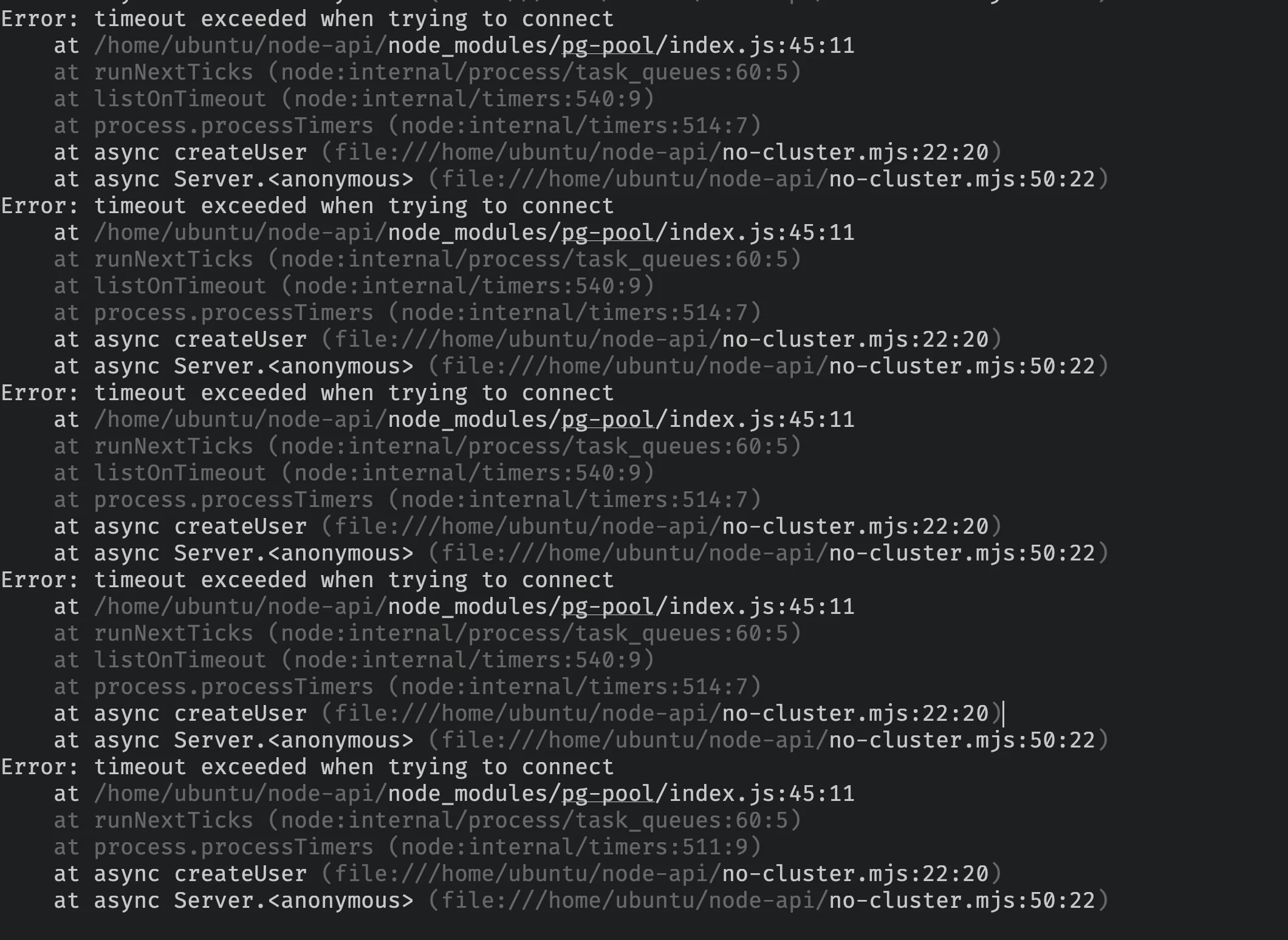
Podemos ver que nossa conexão Postgres está atingindo timeout, o connectionTimeoutMillis atual está configurado para ser 2000 (2s), vamos tentar aumentar isso para 30000 e ver se isso melhora nosso teste de carga.
Podemos fazer isso mudando a linha 13 de index.mjs de 2000 para 30000:
connectionTimeoutMillis: 30000Vamos executar novamente:
./start.sh 3000E o resultado?
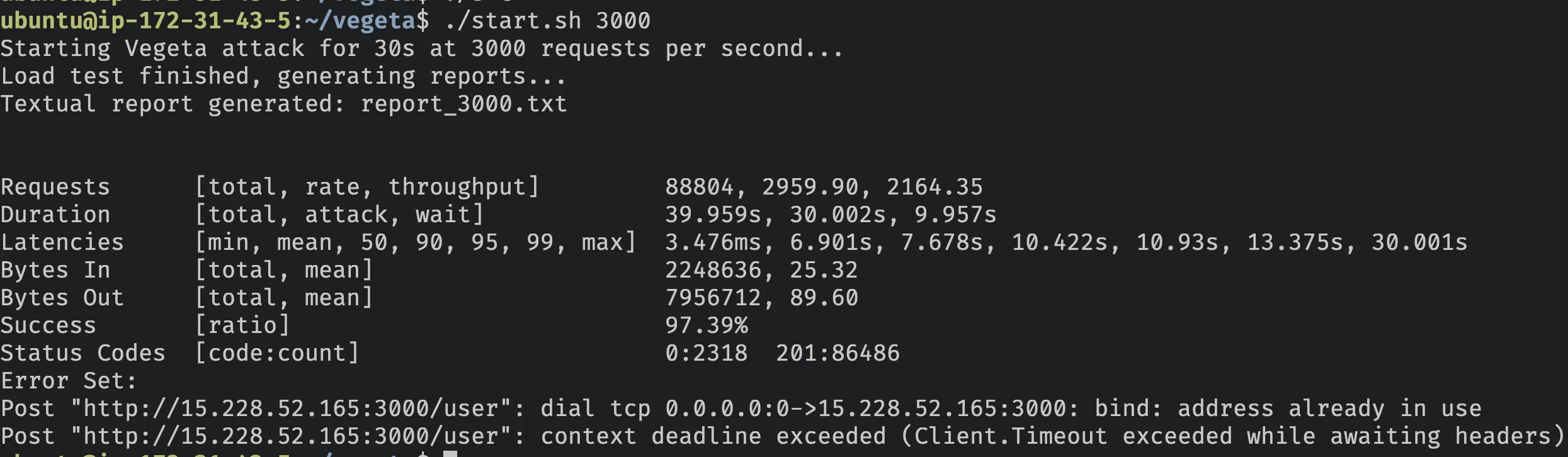
| Métrica | Valor |
|---|---|
| Requisições por Segundo | 2959.90 |
| Taxa de Sucesso | 97.39% |
| Tempo de Resposta p99 | 13.375 s |
| Tempo de Resposta Médio | 6.901 s |
| Tempo de Resposta Mais Lento | 30.001 s |
| Tempo de Resposta Mais Rápido | 3.476 ms |
| Código de Status 201 | 86486 |
| Código de Status 0 | 2318 |
Legal, ao simplesmente aumentar o timeout de conexão para o banco de dados melhoramos a taxa de sucesso em 45,19%, além disso, todos os erros 500 agora desapareceram completamente!
Vamos dar uma olhada nos erros restantes (código de status 0).

Código de status 0 geralmente significa que o servidor resetou a conexão porque não conseguiu lidar com mais.
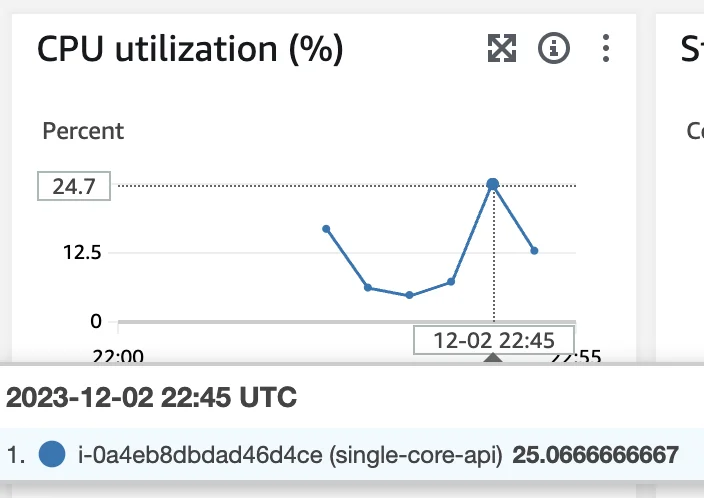
Vamos verificar se é CPU, Memória ou Rede.
No pico do teste, a CPU está consumindo apenas 13%, então não é CPU.
Ao executá-lo novamente com htop notei que a memória estava em cerca de 70%, então isso também não é o problema:

Vamos tentar algo diferente.
File Descriptors
Em sistemas unix, cada nova conexão (socket) é atribuída a um File Descriptor. Por padrão, no Ubuntu, o número máximo de file descriptors abertos é 1024.
Você pode verificar isso executando ulimit -n.

Vamos tentar aumentar isso para 2000 e refazer o teste para ver se conseguimos nos livrar desses 2% de erros de timeout.
Para fazer isso, vou seguir este tutorial e mudar para 6000
sudo vi /etc/security/limits.conf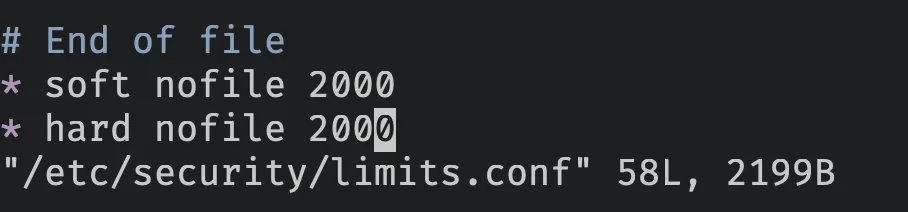
nofile = número de arquivos. soft = limite soft. hard = limite hard.
Então reinicie a EC2 com sudo reboot now.
Após fazer login, podemos ver que o limite mudou:

E vamos refazer o teste:
Inicie a API com
NODE_ENV=production node --env-file=.env index.mjsE inicie o load-tester com:
./start.sh 3000Vamos verificar os resultados:
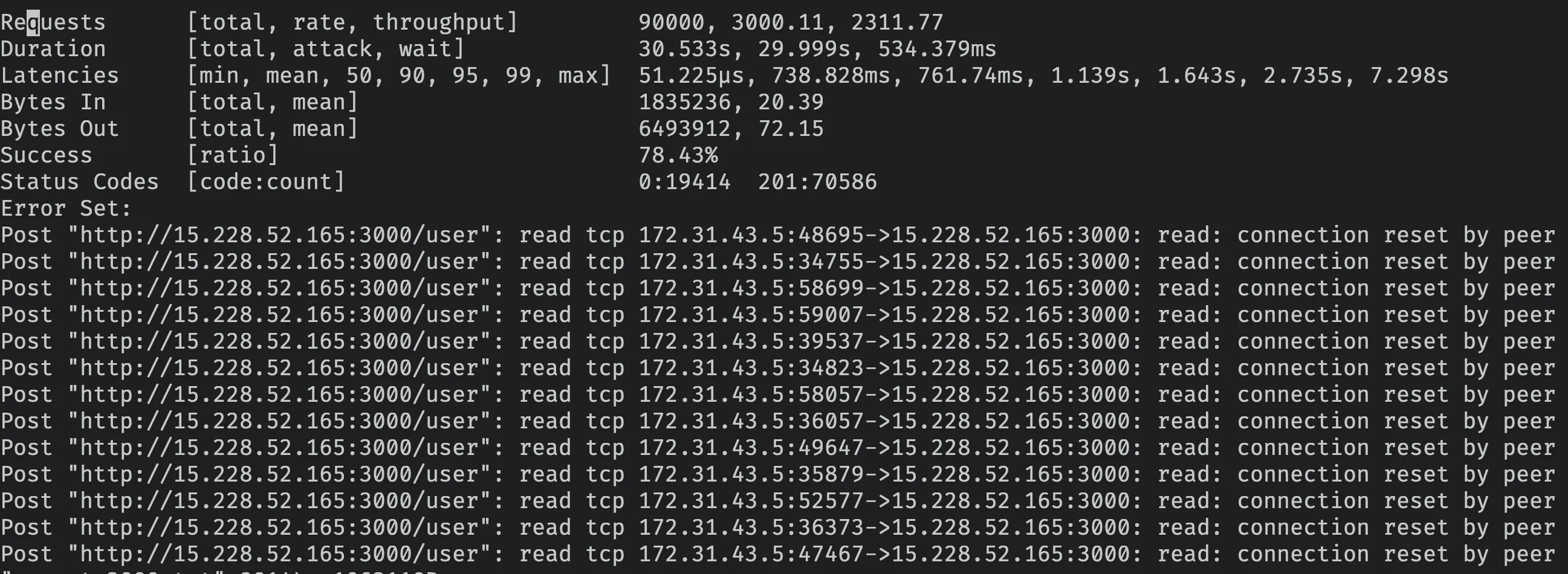
Surpreendentemente, os resultados são piores!
Com um máximo de 2.000 arquivos abertos, a API node respondeu com sucesso apenas 78.43% das requisições.
Isso é porque tendo apenas um core, adicionar mais sockets abertos faz o processador alternar entre os arquivos mais frequentemente que a versão anterior.
Vamos tentar reduzir para 700 para ver se fica melhor.
(Vou pular o passo de como fazer isso porque é o mesmo).
E vamos ver a nova saída com 700 como máximo de arquivos abertos.
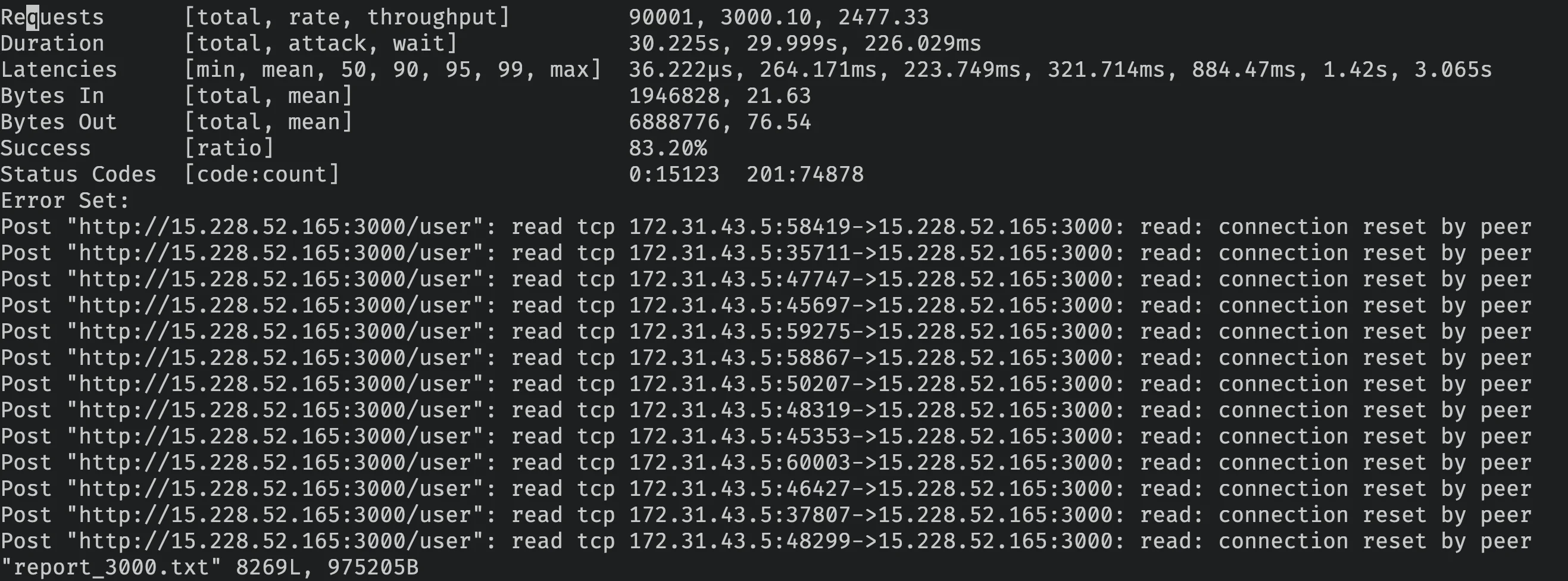
Com 700 arquivos abertos máximos, atingimos 83.20% de taxa de sucesso. Vamos voltar para 1024 e tentar reduzir o connection pool para 20 ao invés de 40.
Se isso não funcionar, vamos assumir que 3.000 req/s é ligeiramente maior que o limite e tentaremos encontrar o número máximo de requisições/s que uma API node de single core pode lidar com 100% de sucesso.
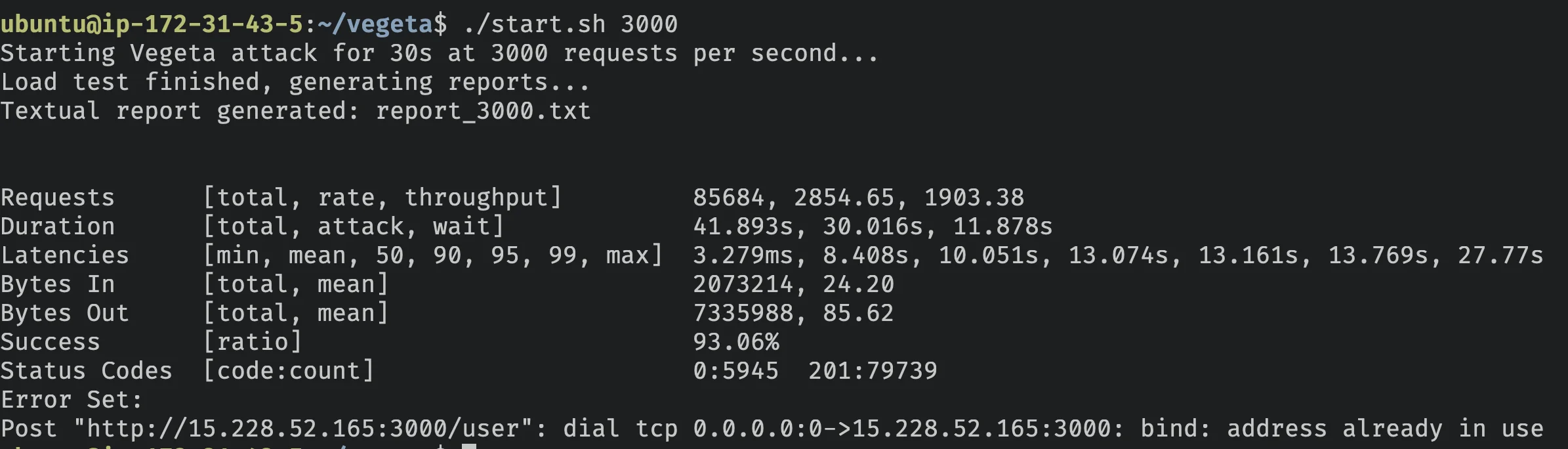
Com 20 conexões para o connection pool, a API foi capaz de processar 93.06%, provando que provavelmente não precisamos de 40.
Vamos tentar com 2.600 reqs/s:
2.600 reqs/s
./start.sh 2600E esse é o resultado:
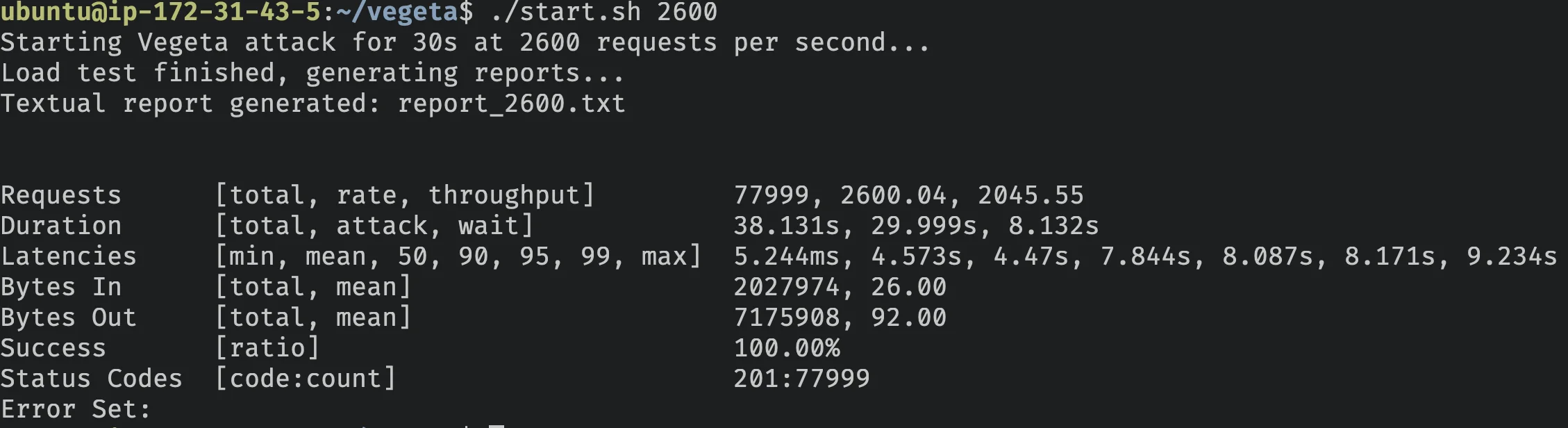
| Métrica | Valor |
|---|---|
| Requisições por Segundo | 2600.04 |
| Taxa de Sucesso | 100% |
| Tempo de Resposta p99 | 8.171 s |
| Tempo de Resposta Médio | 4.573 s |
| Tempo de Resposta Mais Lento | 9.234 s |
| Tempo de Resposta Mais Rápido | 5.244 ms |
| Código de Status 201 | 77999 |
É isso!
Conclusão
Este experimento demonstra as capacidades de uma API Node.js pura em um servidor de single-core.
Com uma API Node.js 21.2.0 pura, usando um único core com 1GB de RAM + connection pool com um máximo de 20 conexões, conseguimos alcançar 2.600 requisições/s sem falhas.
Ao ajustar parâmetros como tamanho do connection pool e limites de file descriptor, podemos impactar significativamente a performance.
Qual é a carga mais alta que seu servidor Node.js lidou? Compartilhe suas experiências!